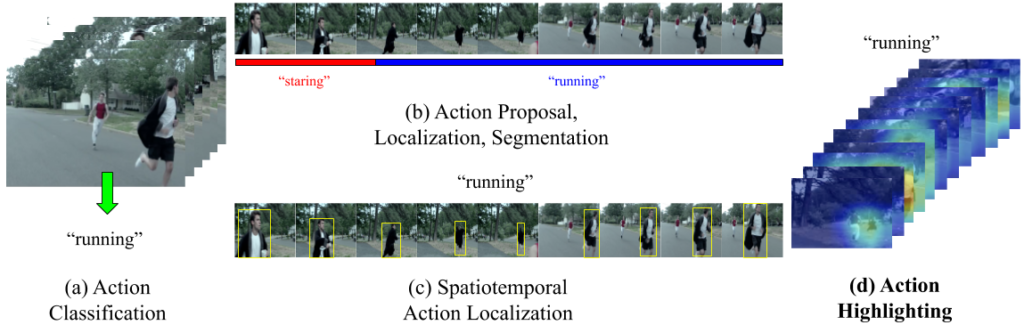
Retrieving and Highlighting Action with Spatiotemporal Reference
※Accepted to ICIP2020 : Arxiv
本研究は、深層学習を用いたクロスモーダル検索の枠組みを用い、人間の行動が動画中のいつ・どこで起こるかを可視化する Action Highlighting を提案する。このタスクに対し我々は、動画と説明文のペアから、動詞・名詞の共起性に着目し、動画中の局所領域に対して表現学習を行い、各時空間ブロックに適切な埋め込みを 3D CNN を用いて学習する。これらの学習された特徴表現を用いることで、新たな動詞を参考に Action Highlighting を行うことが可能となる。
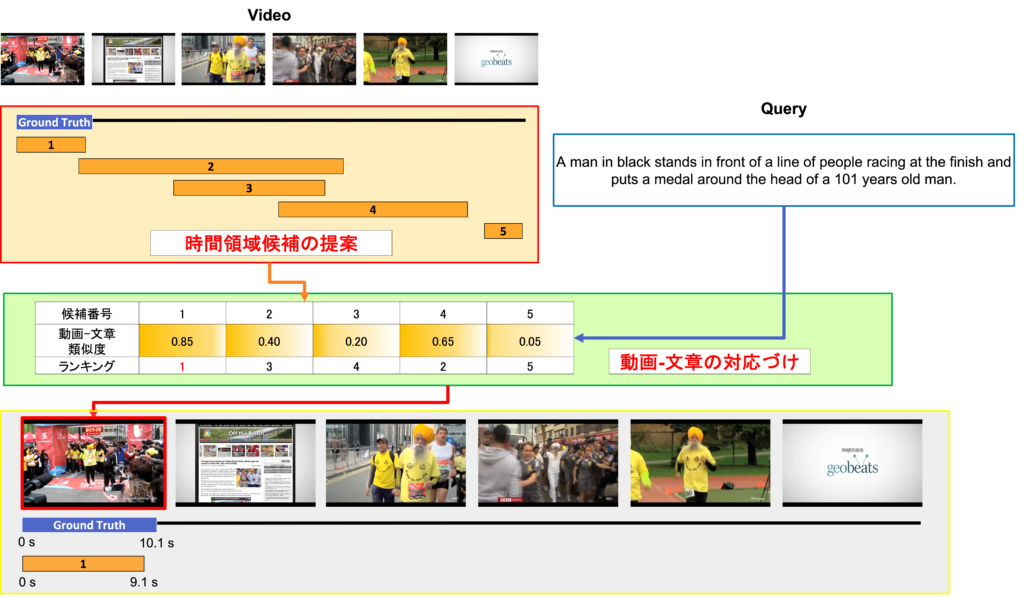
Temporal Action Proposal からのモーメント・文章間マッチング
ビジョンアンドランゲージは視覚的な動画像情報と自然言語から得られる言語情報を融合したマルチモーダルな研究分野である.その中でも本研究では,トリミングされていない動画の一部分を説明した自然言語による入力文章を受けて,動画内からその対応した場面の時系列的なローカライズを行うタスクに取り組んだ.1ステージに既存のTemporal Action Proposalを利用して時間領域候補群を獲得し,2ステージにVideo Grounding using Natural Languageによるアプローチで最適な時間領域を決定するランキング問題として解決を図るproposal and rankな2ステージ型のモデルを提案した.