シーン理解・行動認識
Guided by the Way: The Role of On-the-route Objects and Scene Text in Enhancing Outdoor Navigation
https://2024.ieee-icra.org
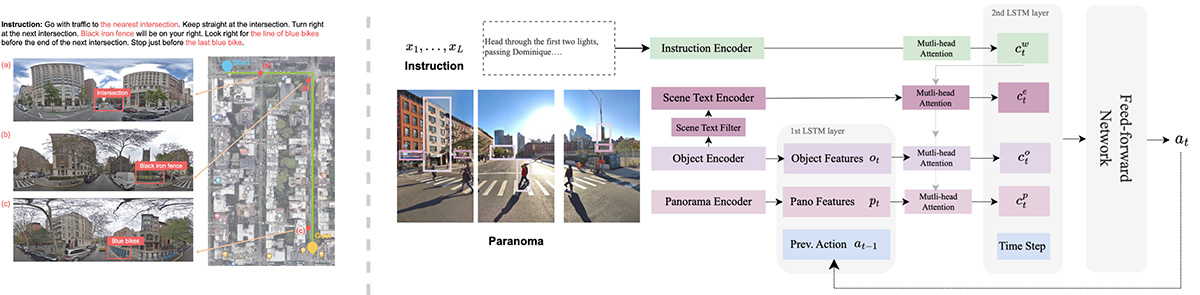
In outdoor environments, Vision-and-Language Navigation (VLN) requires an agent to rely on multi-modal cues from real-world urban environments and natural language instructions. While existing outdoor VLN models predict actions using a combination of panorama and instruction features, this approach ignores objects in the environment and learns data bias to fail navigation. According to our preliminary findings, most instances of navigation failure in previous models were due to turning or stopping at the wrong place. In contrast, humans intuitively frequently use identifiable objects or store names as reference landmarks, ensuring accurate turns and stops, especially in unfamiliar places. To address this insight gap, we propose an Object-Attention VLN (OAVLN) model that helps the agent focus on relevant objects during training and understand the environment better. Our model outperforms previous methods in all evaluation metrics under both seen and unseen scenarios on two existing benchmark datasets, Touchdown and map2seq.
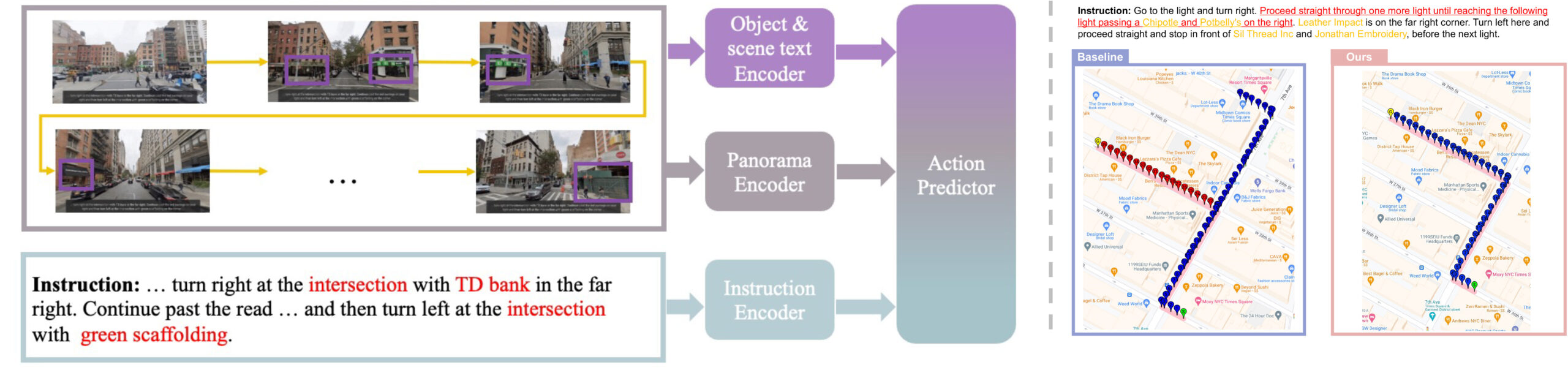
Boosting Outdoor Vision-and-Language Navigation with On-the-route Objects
Vision-and-Language Navigation(VLN)タスクは,ロボットが自然言語の指示を使用して実世界の環境をナビゲートすることを目指している.近年、多くのVLNモデルが提案されてきたが,これらは指示とパノラマ特徴を結合して行動のシーケンスを予測し,特定のセマンティクスや物体認識をしばしば見落としている.予備実験により,既存のモデルが物体トークンに十分な注意を払っていないことが明らかとなった.この傾向は,人間が馴染みのない地域をナビゲートする際にランドマークに頼る様子とは対照的である.そこで,本研究はナビゲーション指示内の物体に焦点を当てるように設計された,エージェントの環境理解を向上させるObject-Attention VLN (OAVLN) モデルを提案する.複数のデータセットでの実験結果から,OAVLNの優越性が示され,オブジェクトを主要なナビゲーションランドマークとして活用し,エージェントを正確に制御する能力が確認された.
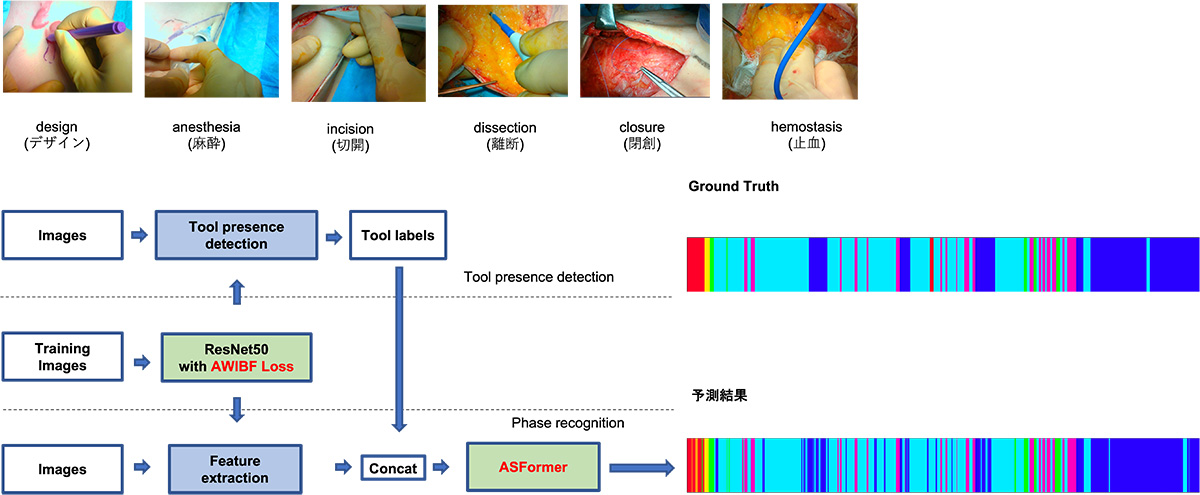
術具情報を考慮した形成外科手術における自動工程分類
本研究では, 形成外科手術動画の手術工程を自動分類するモデルを提案した. 手術動画の中で多く研究されている内視鏡手術に比べ, 形成外科手術動画は手術の種類や体の部位が多様であるため, より汎用的なモデルの構築が必要であった. このような形成外科手術に対して工程分類を行うために, 手術シーンを理解するために重要な術具の情報を加えて学習させることで高精度を達成した. また, 既存の研究では内視鏡手術でのみ行われていた手術シーンの理解を, 他の外科手術に対しても拡張できることを示した.
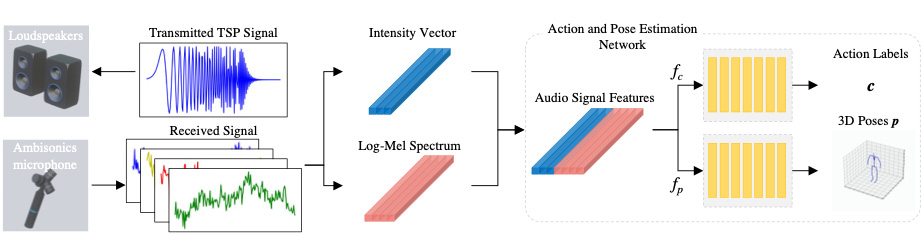
音響情報を用いた人物姿勢推定
音響情報を使用した3次元姿勢推定のための新規フレームワークを提案した.
提案手法は主に
①TSP信号を用いたセンシング
②音響特徴量(Log Mel Spectrum, Intensity Vector)の作成
③1次元CNNを使用した関節座標回帰ネットワーク
の3つのパートから構成されている。音響信号が人の身体で反射した際の振幅の変化や到来方向を捉えることで関節点の3次元座標を高精度で取得することが可能になった.
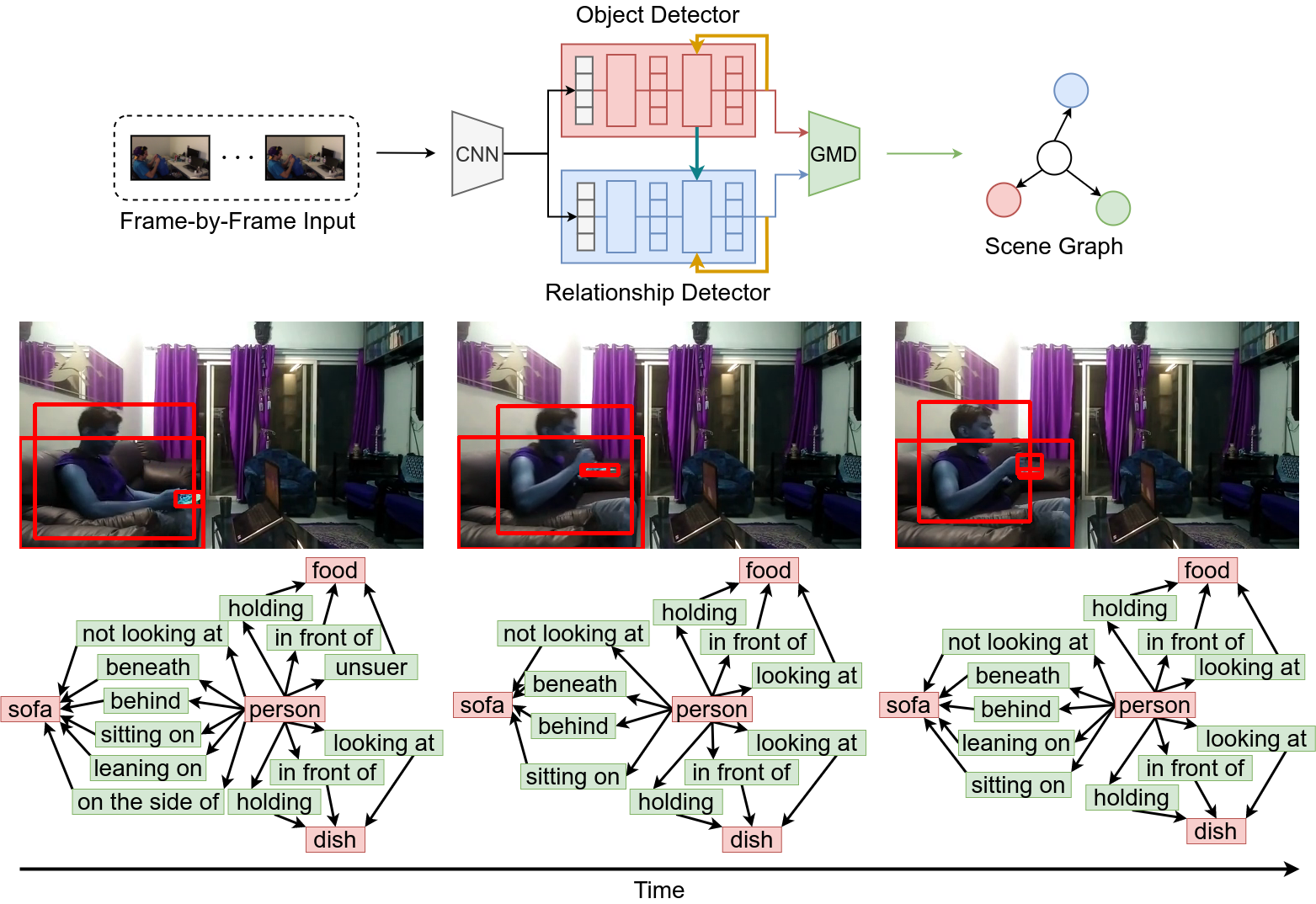
動的シーングラフ生成における物体と関係性の同時検出
動的シーングラフとは,動画における各シーンにおいて物体と物体間の関係性をグラフ構造で詳解することで動画内の包括的な認識を実現する枠組みである.従来は,検出した物体を元に関係性を検出する2段階処理の手法が一般的であったが,このような手法では関係性検出器が物体検出器に依存しており,推論の処理速度がボトルネックとして懸念される.本研究では,物体と関係性を並行して同時に検出することで,物体検出器と関係性検出器の相互学習を実現しつつ,処理速度を向上させる.
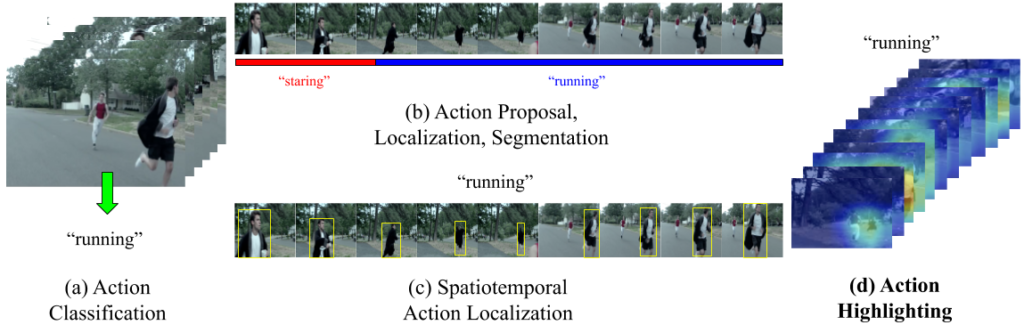
Retrieving and Highlighting Action with Spatiotemporal Reference
本研究は、深層学習を用いたクロスモーダル検索の枠組みを用い、人間の行動が動画中のいつ・どこで起こるかを可視化する Action Highlighting を提案する。このタスクに対し我々は、動画と説明文のペアから、動詞・名詞の共起性に着目し、動画中の局所領域に対して表現学習を行い、各時空間ブロックに適切な埋め込みを 3D CNN を用いて学習する。これらの学習された特徴表現を用いることで、新たな動詞を参考に Action Highlighting を行うことが可能となる。
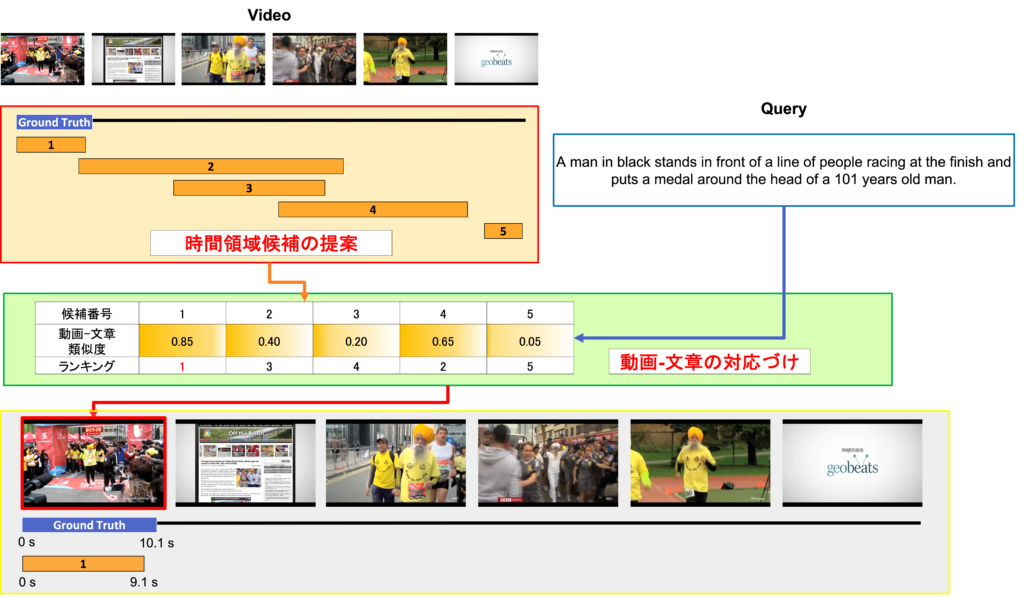
Temporal Action Proposal からのモーメント・文章間マッチング
ビジョンアンドランゲージは視覚的な動画像情報と自然言語から得られる言語情報を融合したマルチモーダルな研究分野である.その中でも本研究では,トリミングされていない動画の一部分を説明した自然言語による入力文章を受けて,動画内からその対応した場面の時系列的なローカライズを行うタスクに取り組んだ.1ステージに既存のTemporal Action Proposalを利用して時間領域候補群を獲得し,2ステージにVideo Grounding using Natural Languageによるアプローチで最適な時間領域を決定するランキング問題として解決を図るproposal and rankな2ステージ型のモデルを提案した.
[/su_animate]
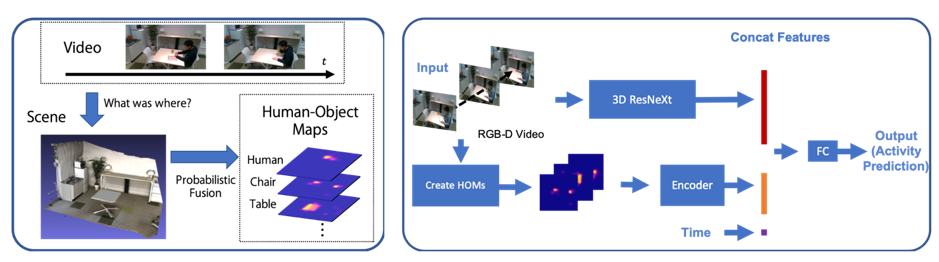
人と物体の存在確率を用いた日常行動認識
数分間・数時間と中長期に行われる日常行動では複数の細かいPrimitiveな行動が多く含み,動画のみの行動認識は難しい.本研究では,人と物体の存在確率マップを生成するシステムと,中長期に渡る人の日常行動データセットを構築し,人が「いつ」「どこで」「何と」「どのように」行動を行ったかの情報を特徴として利用し,同データセットで評価した.人と物体の存在確率を推定して特徴マップ化したHuman-Object Mapsを利用することによって中長期日常行動を高精度に認識することができた.
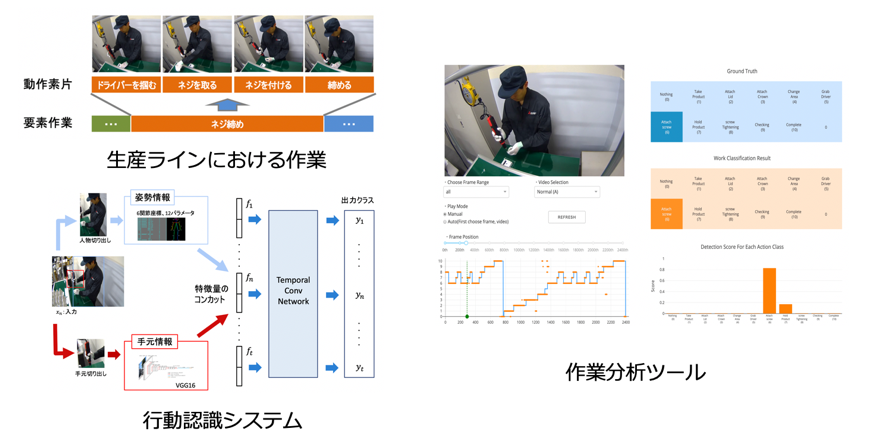
工場生産ラインにおける詳細行動認識
本研究では生産ラインの作業現場おける詳細行動認識を課題とし,各作業を更に細かく分割した動作素片単位における作業の認識を目指した.作業映像の特徴として,主に腕回りのみによる詳細な作業によって構成されているため,画像全体の情報から作業ごとの違いを捉えることは難しい点が挙げられる.そこで,腕の動きを捉えるための上半身の姿勢情報と,道具や手の動きを捉えるための手元情報に注目し,これらを組み合わせた手法を提案した.自作した少数データセットにおいて高い認識率とともに作業者,作業環境の変化に対する頑健性の確保を実現した.また作業分析ツールの作成により,認識結果の可視化も行なった.
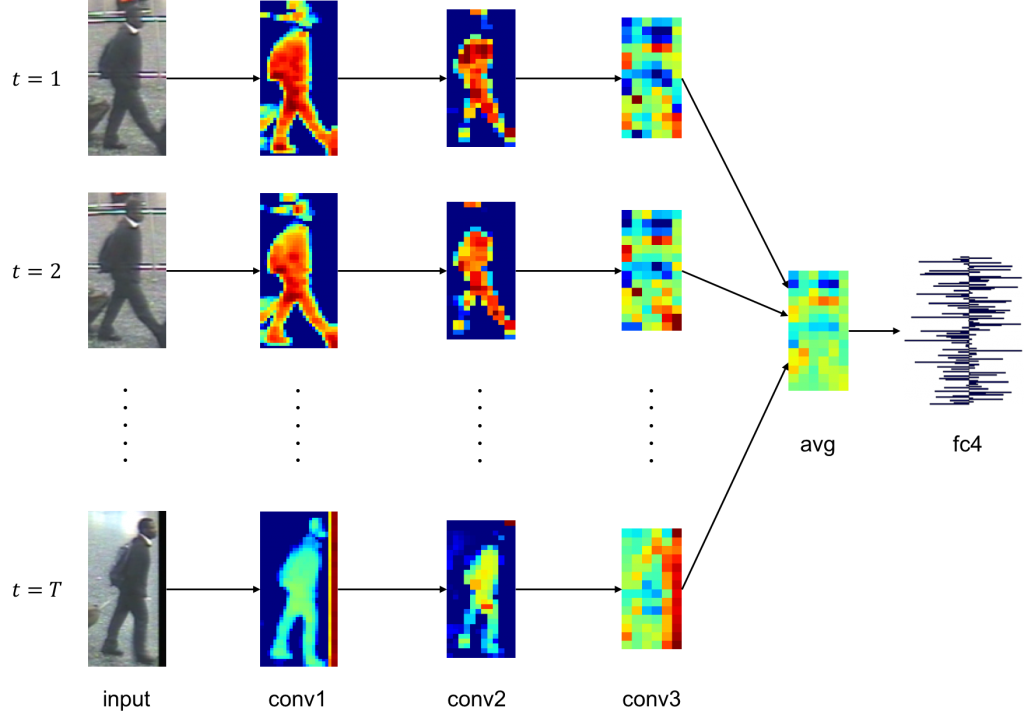
CNNを用いた距離学習による人物再同定
畳み込みニューラルネットワークにより動画像中の人物の類似度を学習することにより人物再同定を行う新たな手法を提案した.各人物動画は畳み込みニューラルネットワークにより特徴抽出がなされ,埋め込みベクトル同士の距離が直接人物間の距離指標に対応するようにユークリッド空間へと写像される.Entire Triplet Lossと呼ばれる改良されたパラメータ学習手法により,ミニバッチ内で取りうる全てのTripletの組が考慮された上で一度のパラメータの更新が行われる.このようなパラメータ更新手法の簡素な変更によりネットワークの汎化性能が大きく向上し,埋め込みベクトルがより人物毎に分離し易くなった.評価実験により,国際的なデータセットにおいて最先端の再同定率を達成した.
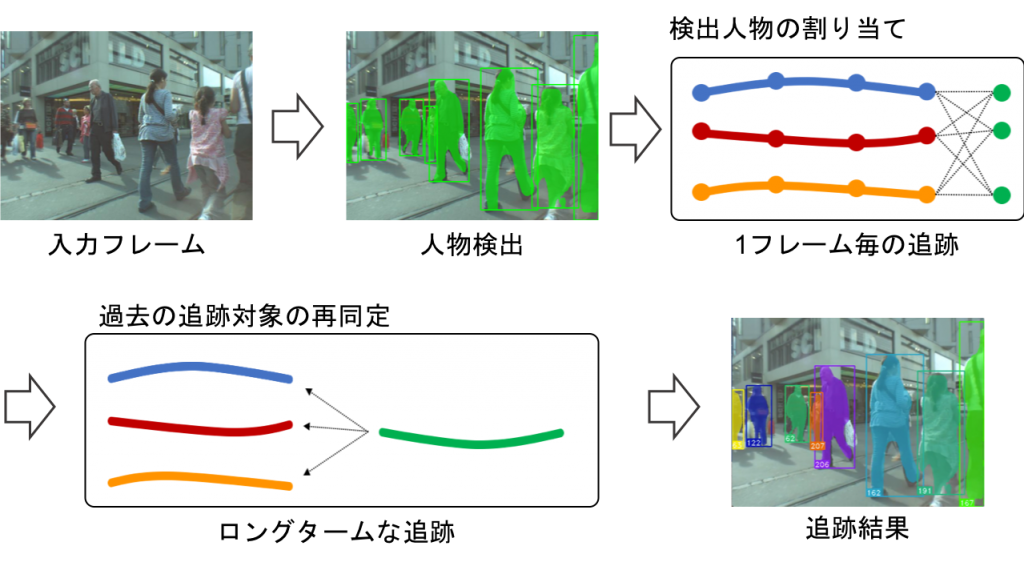
追跡軌跡の再同定を用いたオンライン複数物体追跡
オンライン処理による複数物体追跡の既存手法の多くは,動画の毎フレームで物体検出を行うことによって得られる物体矩形を時系列的に割り当てていくtracking-by-detectionのアプローチを取っている.しかし,既存手法では遮蔽などによって物体検出器で未検出となった対象を追跡することはできなかった.そこで,追跡軌跡の再同定により一度消失した対象を再び追跡状態へと移行させる手法を提案する.物体の高次元な見え特徴を表す埋め込みベクトルを畳み込みニューラルネットワークを用いて取得し,追跡軌跡同士の埋め込みベクトルの距離によって追跡軌跡の再同定判定を行う.このとき,ネットワークの入力に領域分割によって得られた物体のマスク画像を用いることで,背景変化に頑健な再同定判定を行うことが可能である.また,追跡軌跡ペアの再同定判定は低次元なベクトル同士の距離に基づいて行われるため,再同定判定を行うことによる計算コストの増加は僅かである.
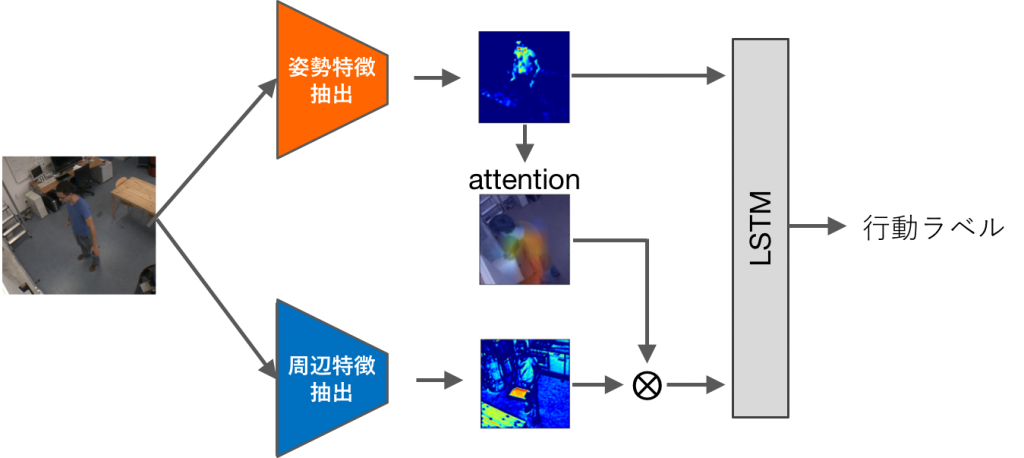
行動遷移映像における時系列行動認識
本研究では,複数行動が連続的に遷移していく映像を対象とした行動認識を課題とし,階層的なLSTMを用いて多様な時系列解析を行うことを提案した.また,環境変化に頑健な姿勢情報を中心としながら,周辺情報を付加的に学習させることと,姿勢特徴によって周辺特徴のフィルタリングを行うことで周辺特徴をより有効に活用することを提案した.データセットを用いた行動遷移映像における行動認識課題を対象に,従来手法からの改善を得ることが出来た.
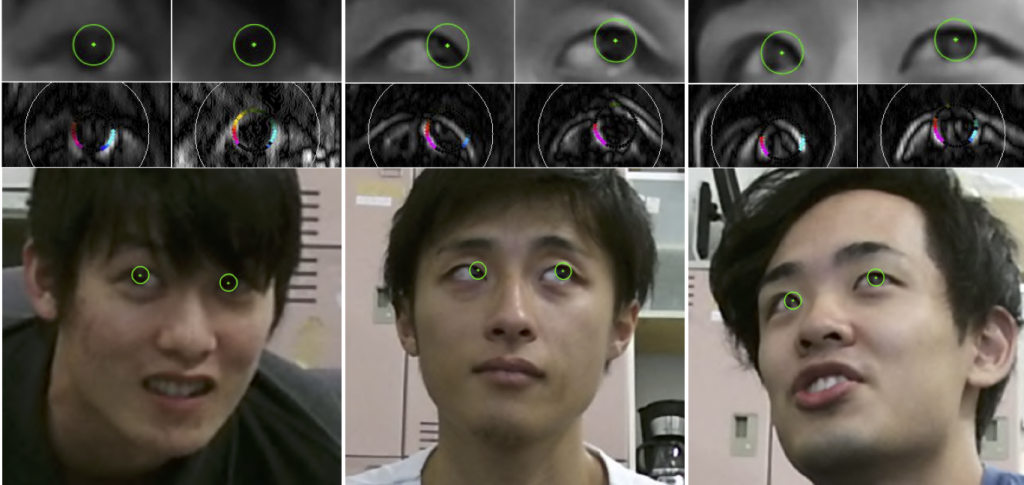
キャリブレーションフリー視線推定
既存の視線推定手法は,赤外線LEDや距離センサ等,特別な装置を用いたり,事前のキャリブレーション作業が必要なものが多かった.本研究では,社会での実利用に即した視線推定手法の実現へ向けて,キャリブレーションフリーかつカメラに対して広範囲な頭部位置で利用可能な注視点推定手法を提案している.解像度に依存しない頑健な虹彩追跡手法を基盤とし,顔特徴点検出,虹彩追跡,注視点推定から構成される視線推定手法により,広範囲空間内におけるキャリブレーションフリーな視線推定が実現可能であることを示した上で,様々な分野への応用を目指している.