機械学習の効率化
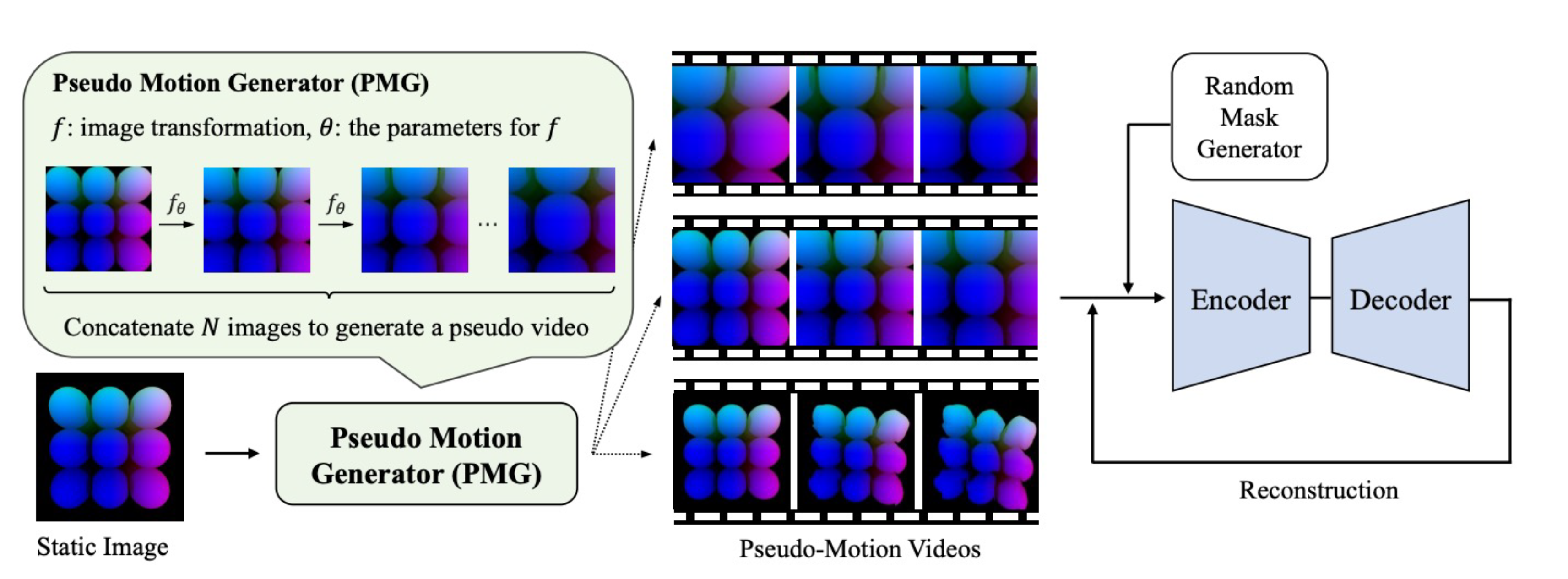
Data Collection-free Masked Video Modeling
video transformerの事前学習には一般に大量のデータが必要であるが、大量の動画を収集・使用することは、コストが高いだけでなく、プライバシー、ライセンス、バイアスなどの問題が伴う。人工データを使用することは、これらの問題を解決する有望な方法の一つであるが、人工データのみで事前学習を行うことには依然として難しい課題である。本論文では、容易に入手可能で低コストな静止画像を活用して、動画認識モデルのための自己教師あり学習のフレームワークを提案する。提案法では、静止画に対して画像変換を再帰的に適用することで、擬似的な動きを持つ動画を生成する Pseudo-Motion Generator(PMG)モジュールを用いる。PMGによって生成された動画は、その後Masked Video Modelingの学習に活用される。本アプローチは、自然画像だけでなく人工画像にも適用可能であり、動画認識モデルの事前学習における、データ収集コストや実データに関するその他の懸念を解消することが可能である。行動認識タスクにおける実験を通じて、このフレームワークが擬似的な動きを持つ動画を通じて、時空間特徴の効果的な学習を可能にすることを示した。提案手法は、静止画像を使用する既存の手法を大幅に上回り、実動画と人工動画の両方を使用する手法の一部を凌駕することを確認した。
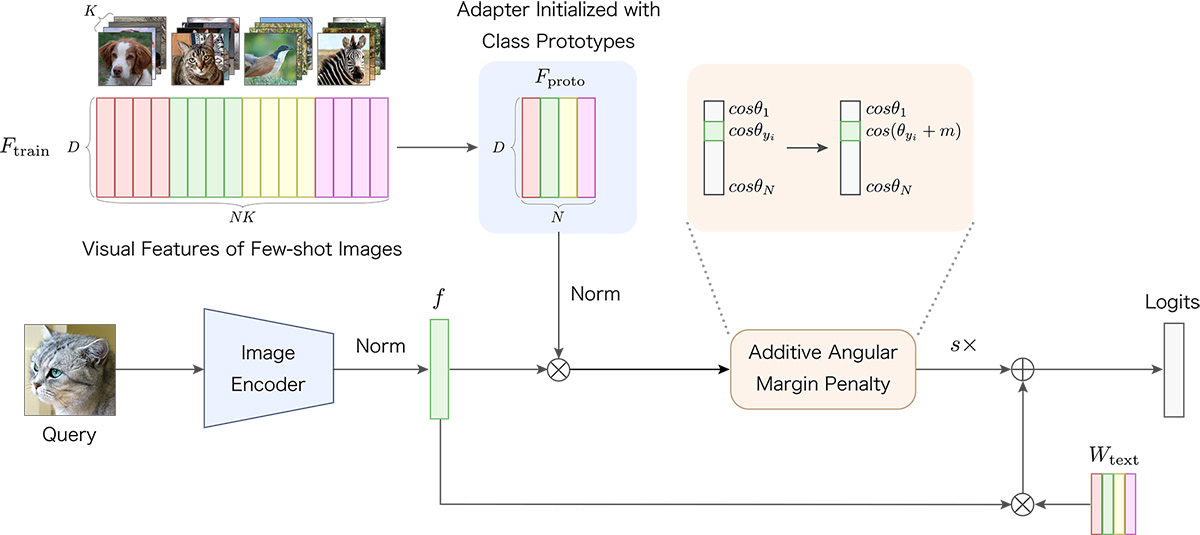
Proto-Adapter: Efficient Training-Free CLIP-Adapter for Few-Shot Image Classification
大量のデータを取得することが困難な応用先において、少数データ学習による画像認識が必要とされる。大規模なvision-languageモデルであるCLIPは、任意のクラスの画像をゼロショットで認識することができる一方で、下流タスクに対する性能には改善の余地が存在する。我々は、少数の学習データを用いてCLIPを下流タスクへ適応させる新たな手法であるProto-Adapterを提案する。本手法はクラス毎のプロトタイプ表現を用いて軽量なアダプターを構築することで、最小限の追加コストで下流タスクの性能を大幅に改善することが可能である。11種類の画像認識ベンチマークを用いた実験により、提案手法の有効性を確認した。
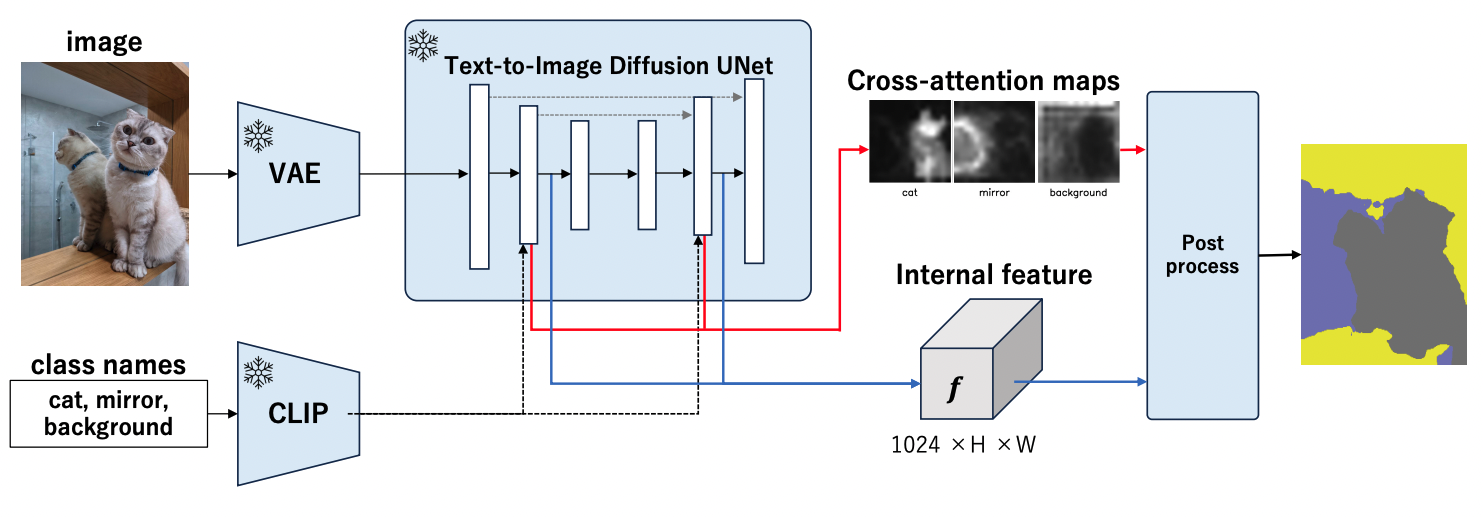
MaskDiffusion: Exploiting Pre-trained Diffusion Models for Semantic Segmentation
MaskDiffusionは、学習済みの拡散モデルを活用した、追加の訓練やアノテーションを必要とせずにオープンボキャブラリーのセマンティックセグメンテーション手法である。我々は、MaskDiffusionが細かい固有名詞ベースのカテゴリーを含むオープンボキャブラリーを扱う際に優れた性能を発揮することを実証し、セグメンテーションの応用範囲を拡大する。MaskDiffusionは、Potsdamデータセット(+10.5mIoU)やCOCO-Stuff(+14.8mIoU)など、他の同等の教師なしセグメンテーション手法と比較して定性的、定量的に大きな改善を示している。
Arxiv: https://arxiv.org/abs/2403.11194
Code : https://github.com/Valkyrja3607/MaskDiffusion
TAG: Guidance-free Open-Vocabulary Semantic Segmentation
我々は、トレーニング、アノテーション、ガイダンスを必要としないオープンボキャブラリーセマンティックセグメンテーションを実現する新しいアプローチ、TAGを提案する。TAGは、CLIPやDINOのような事前に訓練されたモデルを利用し、追加の訓練や密なアノテーションなしに、画像を意味のあるカテゴリにセグメンテーションする。外部データベースからクラスラベルを取得し、新しいシナリオに適応する柔軟性を提供する。TAGは、PascalVOC、PascalContext、ADE20Kにおいて、クラス名を指定しないオープンボキャブラリのセグメンテーションで最先端の結果を達成している。

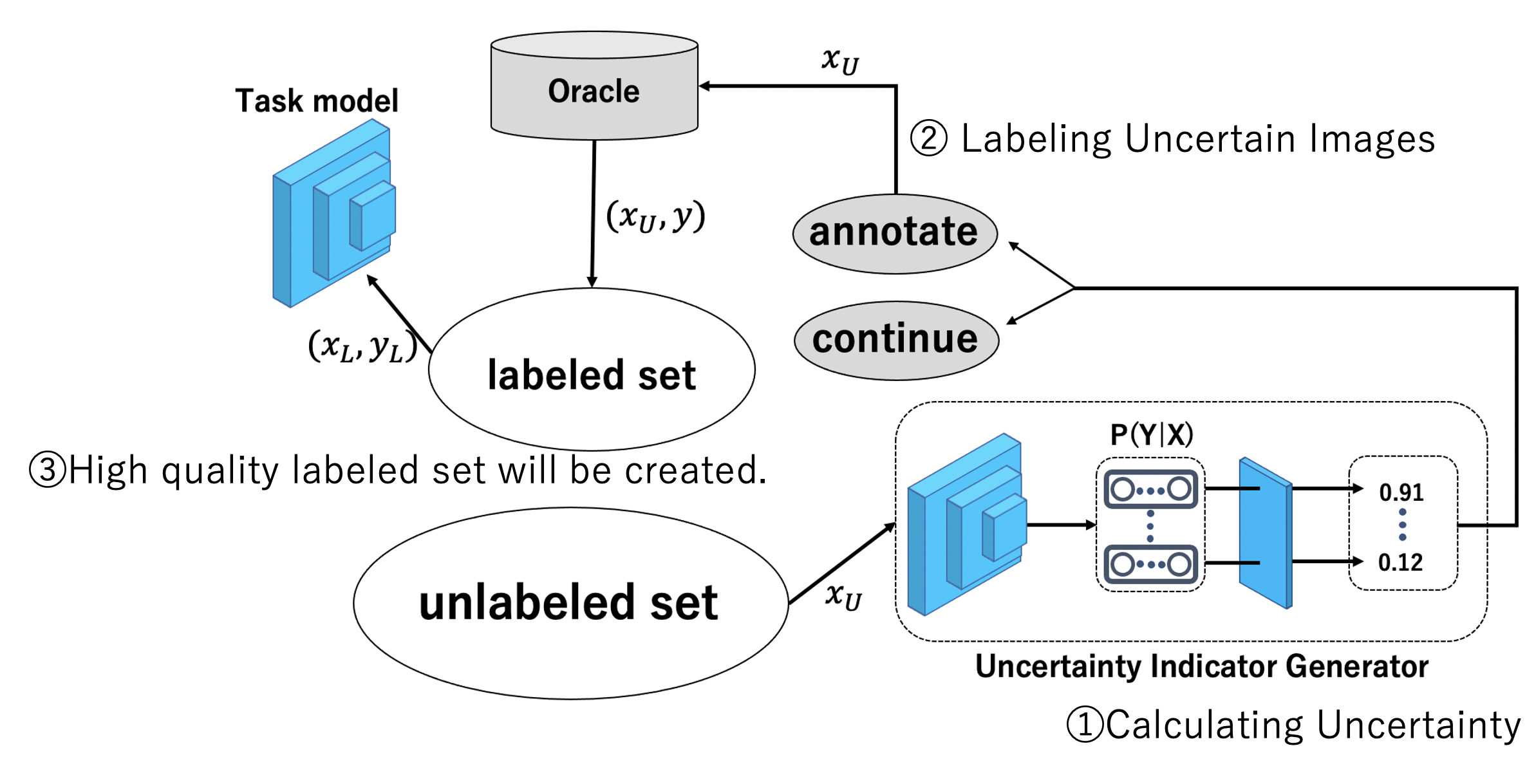
Non-Deep Active Learning for Deep Neural Networks
Active Learningとは,教師データを作る際にラベル付けされるべき最も代表的なサンプルをサンプリングすることで,ラベル効率の高いアルゴリズムを設計することである.本研究ではタスクモデルの出力結果から,最も情報量の多いラベル付けされていないサンプルを導出するモデルを提案する.タスクは分類問題,マルチラベル分類とセマンティックセグメンテーション問題の三つを扱う.本モデルは不確実性指標生成器とタスクモデルで構成されている.ラベル付きサンプルでタスクモデルを学習させた後,ラベル無しサンプルをそのタスクモデルに予測させる.その予測結果から不確実性指標生成器がラベル無しサンプルごとの不確実性指標を出力.不確実性指標の高いサンプルを情報量が多いとみなし,サンプルの選択を行う.複数のデータセットを用いた実験の結果,本モデルは従来のActive Learning手法よりも高い精度を得ることができ,実行時間を最大約10分の1に短縮することに成功した.