画像/動画の認識・生成
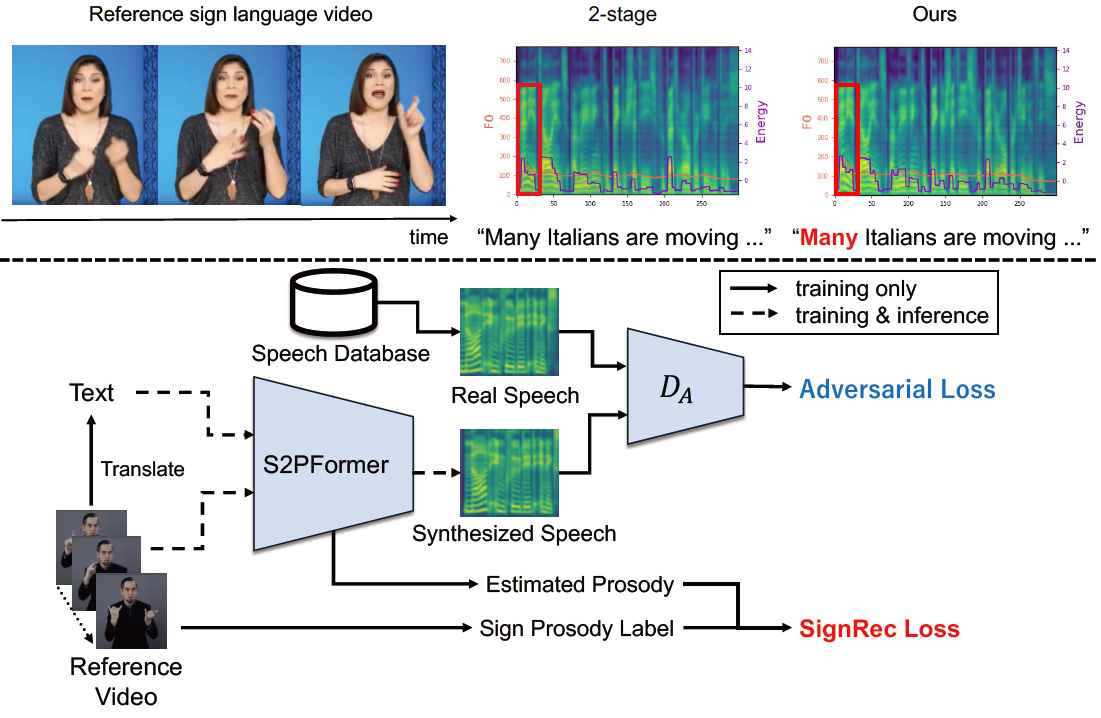
Sign-to-Speech Prosody Transfer
手話は聴覚障害者にとって不可欠なコミュニケーション手段である。近年、深層学習技術により手話からテキストへの翻訳性能が向上し、非手話使用者でも手話のメッセージを理解しやすくなった。しかし、手話には強調や抑揚といった、テキストでは表現できない韻律が含まれており、既存システムはこれを十分に捉えられない。現在主流の2-stage pipeline(sign-to-text → text-to-speech)はテキストのみを仲介とするため、手話動作に宿る韻律の詳細が大幅に失われてしまう。そこで本研究では、手話がもつ韻律のニュアンスを直接合成音声へ統合する「Sign-to-Speech Prosody Transfer」タスクを新たに提案する。このタスクには三つの大きな課題が存在する。(1) 手話翻訳自体が高度であり、手話と音声を対にした高品質データセットが存在しない。(2) 音声の韻律自体が複雑で、翻訳過程にさらなる難易度が加わる。(3) 手話の韻律と対応する音声の韻律の対応は微妙で、直接マッピングする既存手法がない。これらを解決するため、S2PFormer(Sign-to-Prosody Transformer)を提案する。本モデルはSign language prosody reconstructionを活用し、手話と音声の直接対応を必要としないunpairedデータセットでの学習を可能にする。さらに人体の関節情報とテキストの情報にCross-attentionを適用することで、微細な韻律を捉える。広範な実験により、提案手法が手話の韻律を反映した音声を合成できることが確認され、より自然な手話コミュニケーションの実現に向けて新たな可能性を開く。
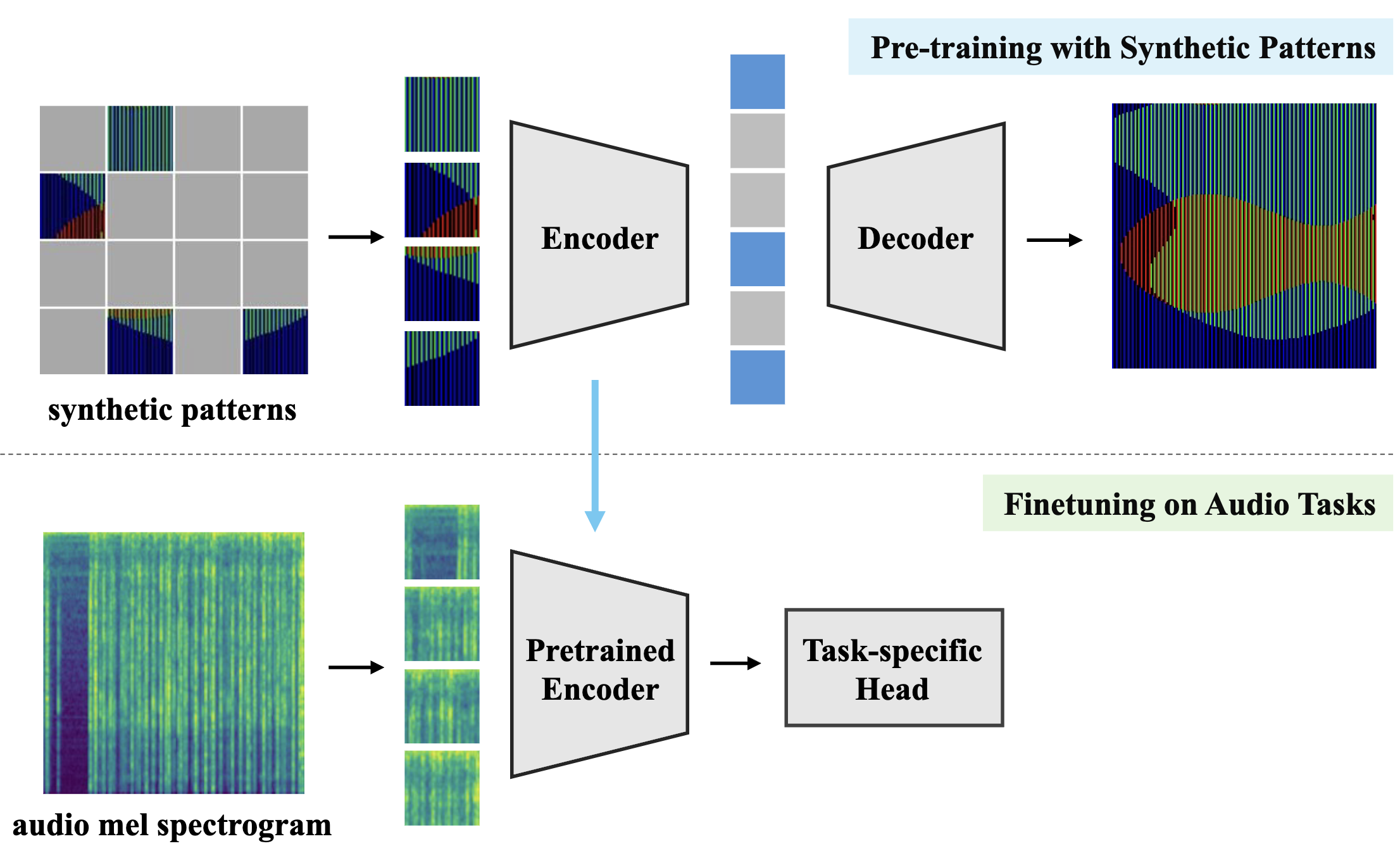
Pre-training with Synthetic Patterns for Audio
本論文では、実音声データの代替として合成パターンを用いて音声エンコーダを事前学習させる手法を提案する。提案フレームワークは二つの主要要素から構成される。第一の要素は Masked Autoencoder(MAE)である。MAE はランダムにマスクした入力から元のデータを再構成する自己教師あり学習フレームワークであり、データ内部の視覚的パターンや規則といった低レベル情報に着目する傾向がある。このため、入力が画像、音声メルスペクトログラム、さらには合成パターンであっても、その内容自体は重要ではない。第二の要素は合成データである。合成データは実音声と異なり、プライバシーやライセンス侵害の問題が存在しない。MAE と合成パターンを組み合わせることで、実データに依存せず汎化的な特徴表現を学習しつつ、実音声が抱える諸問題を回避できる。提案フレームワークの有効性を検証するために、13 種類の音声タスクと 17 種類の合成データセットにわたる大規模実験を実施し、どのタイプの合成パターンが音声に効果的であるかを分析した。その結果、本手法は AudioSet-2M で事前学習したモデルに匹敵する性能を示し、画像ベースの事前学習法を部分的に上回ることが確認された。
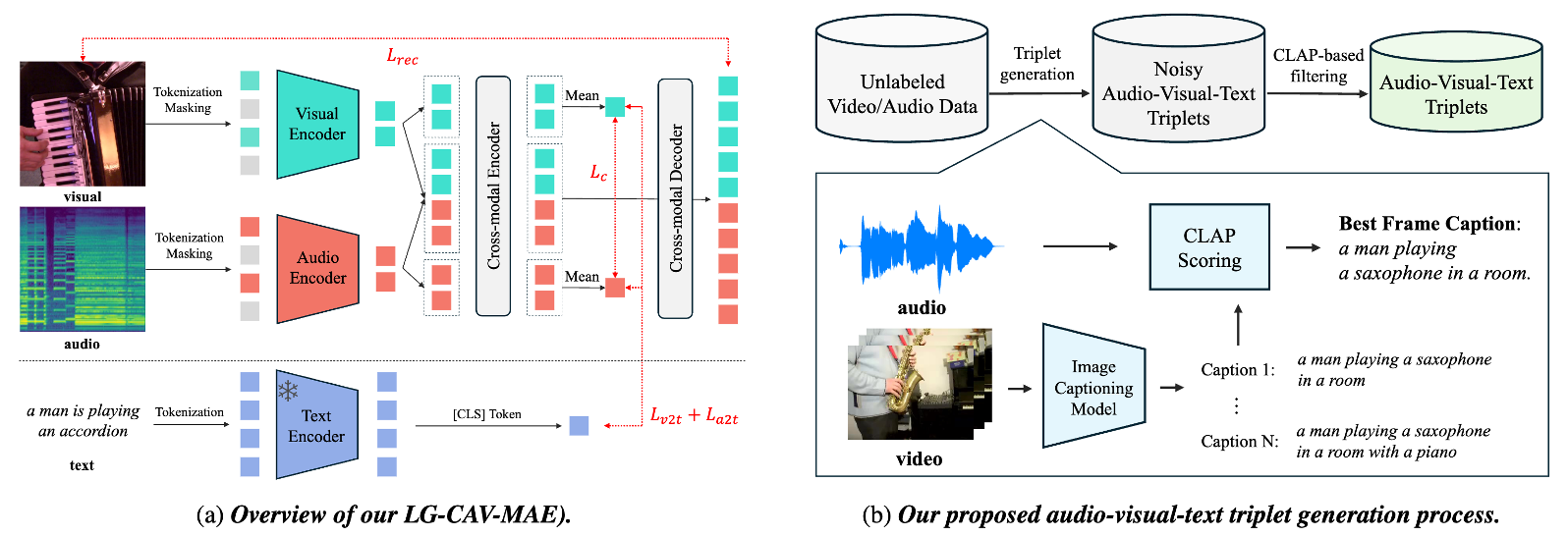
Language-Guided Contrastive Audio-Visual Masked Autoencoder with Automatically Generated Audio-Visual-Text Triplets from Videos
本論文では、視聴覚表現学習を向上させるために Language-Guided Contrastive Audio-Visual Masked Autoencoders(LG-CAV-MAE)を提案する。LG-CAV-MAE は、事前学習済みテキストエンコーダーを、音と映像の対照学習、Masked AutoEncoder の2つと統合し、音声・映像・テキストの3つのモダリティにまたがる学習を可能にする。LG-CAV-MAE を学習させるために、ラベルなし動画から音・映像・テキストのトリプレットを自動生成する手法を導入する。まず画像キャプション生成モデルでフレームレベルのキャプションを生成し、その後に CLAP に基づくフィルタリングを適用して音声とキャプションの高い整合性を保証する。本手法により、手動アノテーションを必要とせず、高品質な音声・映像・テキストのトリプレットを得ることができる。LG-CAV-MAE を音声・映像検索タスクおよび音声・映像分類タスクで評価した結果、既存手法を大きく上回り、検索タスクでは recall@10 を最大 5.6% 向上させ、分類タスクでは 3.2% の改善を達成する結果となった。
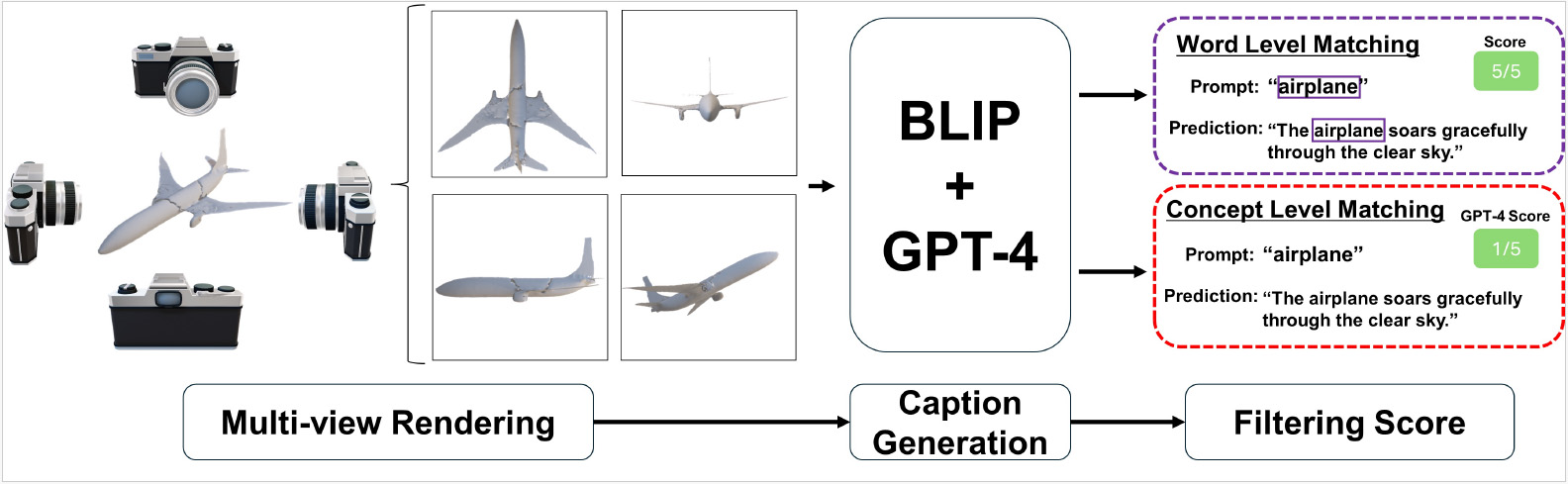
Text-guided Synthetic Geometric Augmentation for Zero-shot 3D Understanding
ゼロショット認識モデルが十分な汎化性能を発揮するためには,多量の訓練データが不可欠である.しかしゼロショット 3D 分類に必要な 3D データとキャプションの収集は高コストであり,大きな障壁となっている.一方,近年の生成モデルは合成データの写実性をかつてないレベルまで高めており,生成データを学習データとして活用できる可能性が示されつつある.そこで,「生成モデルが生み出す合成 3D データで,限られた 3D データセットを拡張できるか?」という問いが生じる.この問いを明らかにするために,本研究では,合成 3D データセット拡張手法「 Text-guided Geometric Augmentation(TeGA)」を提案する.TeGA は,ゼロショット 3D 分類で最先端性能を誇る言語・画像・3D 事前学習に合わせて設計されており,text-to-3D 生成モデルを用いて不足する 3D データを補完・拡張する.具体的には,テキストに従って自動生成した合成 3D データに対し,テキストと幾何形状の意味が一致しないノイズサンプルを除去する一貫性フィルタリング戦略を導入する.TeGA により元データセット規模を 2 倍に拡張した実験では,ベースラインを上回る性能向上が確認され,Objaverse-LVIS で +3.0 %,ScanObjectNN で +4.6 %,ModelNet40 で +8.7 % のゼロショット精度向上を達成した.これらの結果は,TeGA が 3D データ不足を効果的に補い,限られた実データでも堅牢なゼロショット 3D 分類を実現し得ることを示した.
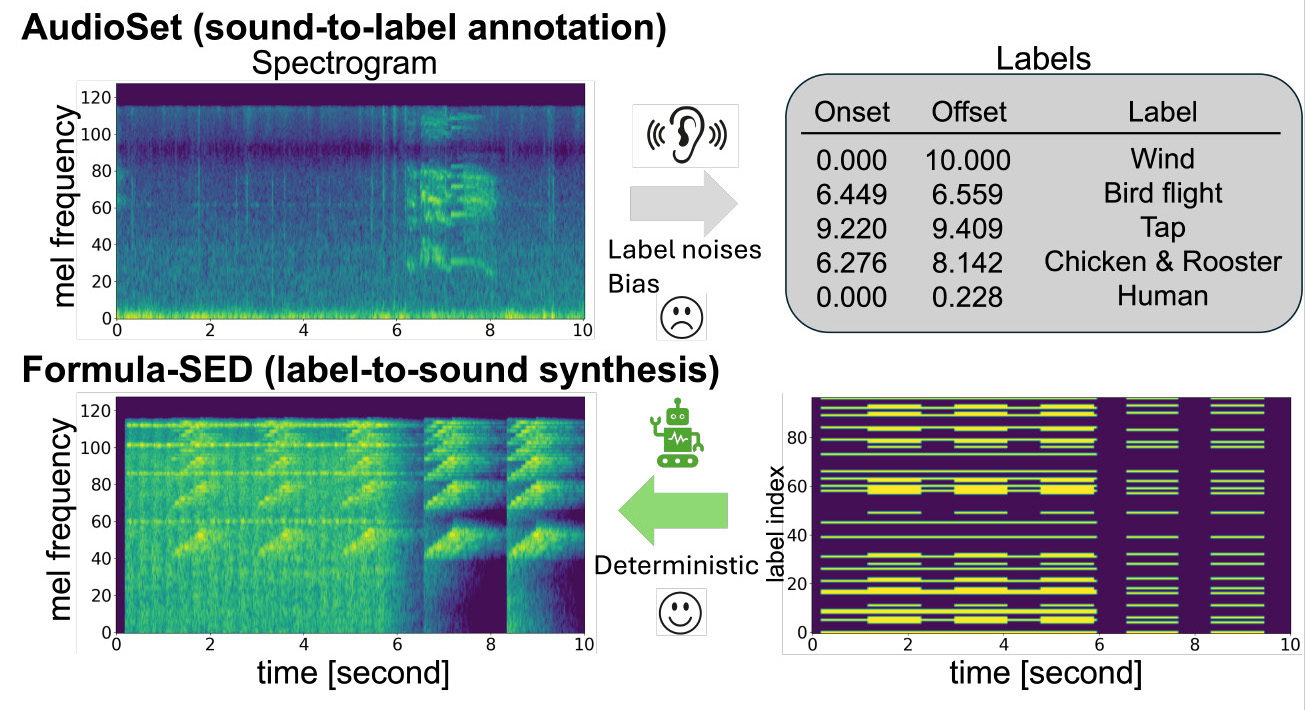
Formula-Supervised Sound Event Detection: Pre-Training Without Real Data
Sound Event Detection(SED)タスクでは、時刻付きラベルの不足や主観的なアノテーションによるノイズが、学習の妨げとなっていた。本研究では数式のみから音響信号を合成し、合成パラメータを正解ラベルとすることで、大規模かつノイズのない事前学習を可能にするデータセット、Formula-SEDを提案する。DESEDデータセットでの実験により、提案データセットを用いた事前学習が精度と収束速度の両面で有効であることを示した。
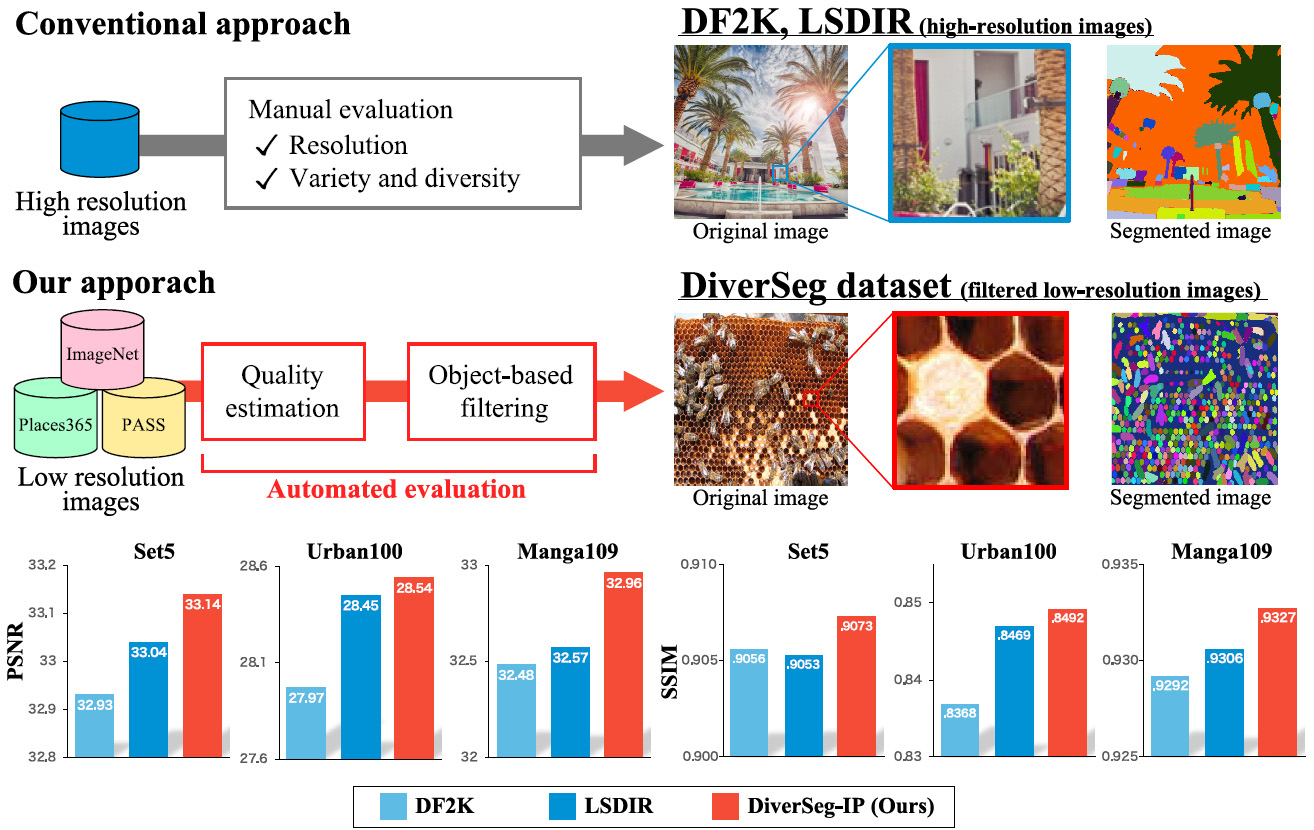
Rethinking Image Super-Resolution from Training Data Perspectives
従来,画像超解像分野において,高解像度で圧縮ノイズが少ない画像が超解像学習を成功させる既成概念となっていた.本研究では,Blockiness分布計測による画質評価, 画像セグメント数計測による被写体の多様性,およびこれらがSR学習成功の本質であることを実証する.提案するDiverSegデータセットは,低解像度なWeb収集画像で構成されているにも関わらず,既存の超解像データセットよりも高い性能を示した.
小売商品棚を対象にした画像認識のための大規模データセット構築
小売商品棚を対象にした画像認識のための大規模データセットを作成した. 小売商品棚は, 1枚の画像に大量の商品が同時に存在するという特性上, アノテーションコストが極めて高い. そこで我々は、3DCGを利用してフォトリアルな小売商品棚の画像を作成し, 同時にオブジェクトの3D座標データをもとにアノテーションを自動で付与することで, 200クラス、100,000枚の大規模なデータセットを作成した.
・本研究はパナソニックコネクト社との共同研究成果です.
・データセットはリンク先のページからダウンロード可能(利用は研究目的に限る).

https://yukiitoh0519.github.io/CG-Retail-Shelves-Dataset/
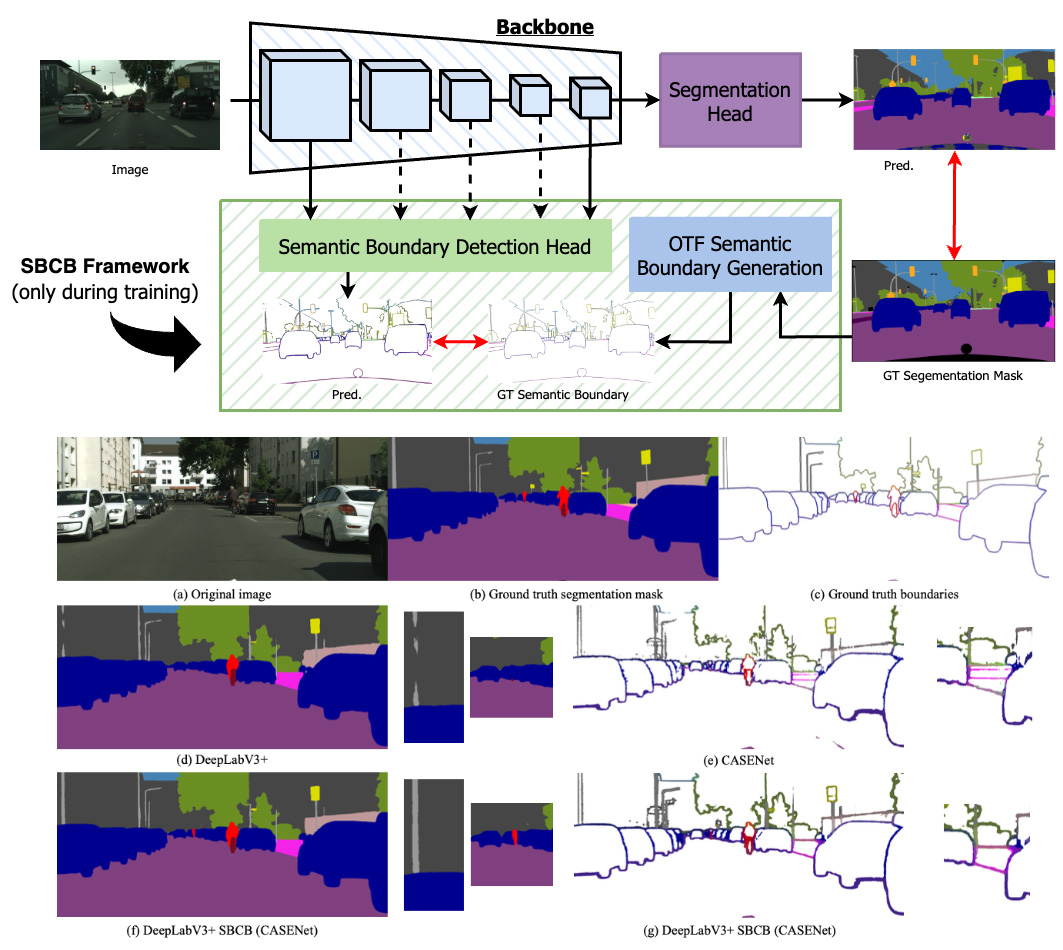
Boosting Semantic Segmentation by Conditioning the Backbone with Semantic Boundaries
Semantic Boundary Conditioned Backbone (SBCB) フレームワークは,多様なセグメンテーション・アーキテクチャとの互換性を維持しながら,特にマスク境界でのセマンティック・セグメンテーションのパフォーマンスを向上させる効果的な学習方法です.このフレームワークは,セグメンテーション・アーキテクチャのバックボーンから得られるマルチスケールの特徴をセマンティック境界検出(SBD)のマルチタスク学習を行い,より境界を理解した特徴を得られます.このアプローチにより,Cityscapes データセットで平均 1.2% の IoU 向上と 2.6% のboundary F スコアの向上が達成でき,セグメンテーションの精度が向上しました。 SBCB フレームワークは,ビジョン・トランスフォーマー・モデルを含むさまざまなバックボーンにうまく適応し,モデルに複雑さを導入することなくセマンティック・セグメンテーションを進歩させる可能性を示しています。
重要パッチ選択に基づく効率的な動画認識
動画は画像と比較して非常に処理コストが高い一方,各フレーム画像は似通っており冗長性が高い.本研究では時間的な動きや変化が小さいパッチを冗長と判断し,入力から除外することで処理コストを削減する動画認識手法を提案した.時間的な動きや変化には圧縮動画を復号する過程で副次的に得られる情報を用いるため,追加で必要な処理コストはパッチを除外することによって削減される処理コストと比較して僅かである.提案手法をTransformerベースの動画認識モデルに適用することで,行動認識において 1 ポイント以下の精度低下で 70 % 以上の処理コスト削減を達成した.

効率的な3DCG背景制作のための360度画像の周辺補完
360度画像は,3DCG制作において効率的にシーンを制作するために,全周囲を表現する背景画像として利用されます.本研究では,1枚の通常画角の画像を入力として,その周囲を補完することで,360度画像を生成する問題に取り組みます.Transformerを用いた提案手法は,先行手法の結果と比べて,より高解像度で自然な見た目の出力画像を得られます.さらに,一つの入力に対して,多様な結果画像を出力することが可能なため,利用者は多くの選択肢を得られます.このようにして,本研究は利用者の効率的でオリジナリティのある3DCG制作の支援を目指しています.

完全合成画像での学習による文書画像の影除去
文書画像に映り込んだ影の除去は,デジタル化された文書の質向上に重要なアプリケーションである.近年の研究では多くの深層学習ベースの影除去手法が提案されており,これらは影がある画像,影のない画像の集合に対して学習する.これらの一般的な教師あり学習手法では,ペアとなる文書画像の大規模なセットが必要であるが,データセットを作成するためには膨大なコストがかかる.そこで本研究では3DCGレンダラを用いて,実際の文書のキャプチャを必要とせず,大規模かつ多様なデータセットを作成する.実験では,提案したデータセットのみで学習したディープニューラルネットワークが実データに対して良好な性能を発揮し,また,事前学習に用いることで性能に向上があることを示した.
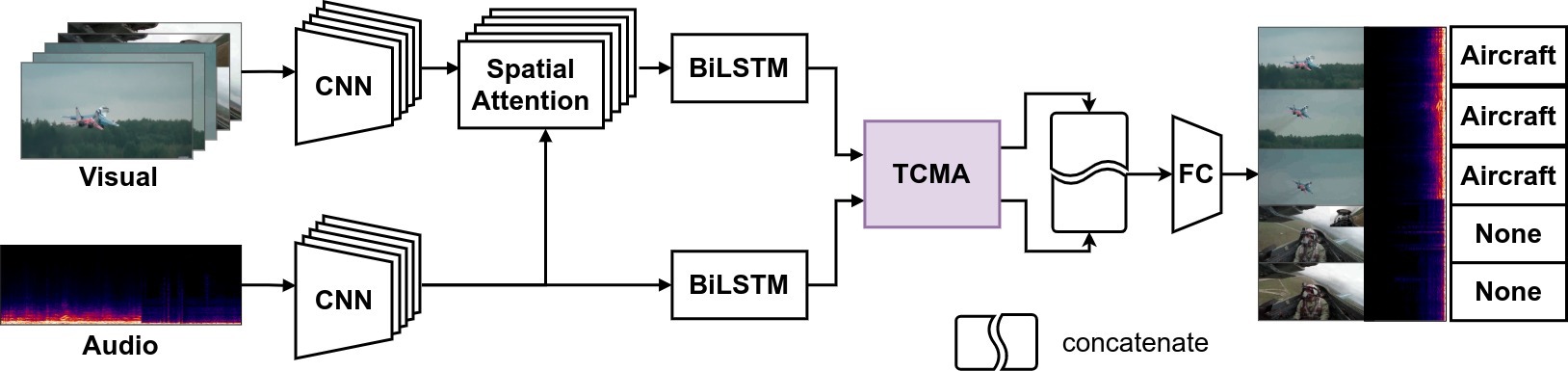
動画内の音と映像によるイベント推定タスクにおける時間方向クロスモーダルアテンションの導入
以前までは,音からの音イベントの認識・検出と映像からのイベントや行動の認識・検出は独立して行われていた.しかし,動画には音と映像が含まれており,音と映像が同一のイベントを表すAudio-Visualイベントにおいては2つのモーダルを利用するほうが認識精度が上がると考えられる.また,Audio-Visualイベントにおいて一方のモーダルは他方のモーダルの教師データに相当する.これにより,教師データを必要とせず自己教師データを利用することで学習を進めることが可能になる.本研究では,Audio-Visualイベントの認識を目的とする.セグメント間の関係性を学習することで動画全体を正確に捉えるために,self-attentionを基盤としてTemporal Cross-Modal Attentionを提案し,先行研究を上回る精度を達成した.
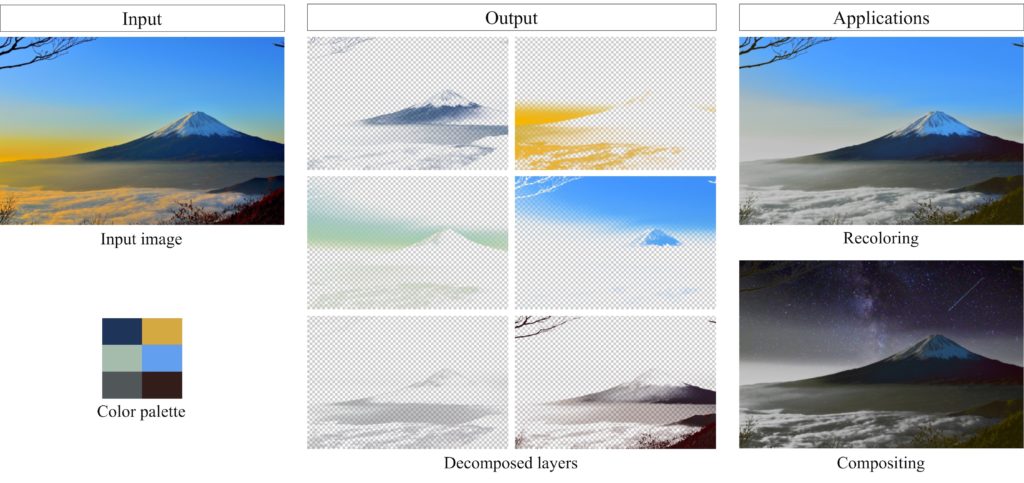
Fast Soft Color Segmentation
この研究では,一枚の画像を似た色のみを含む複数のRGBAのレイヤーに分解する問題を扱う.我々が提案するニューラルネットワークベースの手法は,既存の最適化ベースの手法に比べて30万倍高速に分解できる.その高速な分解の利点により,ビデオの色の変更などの新しい応用を実現する.
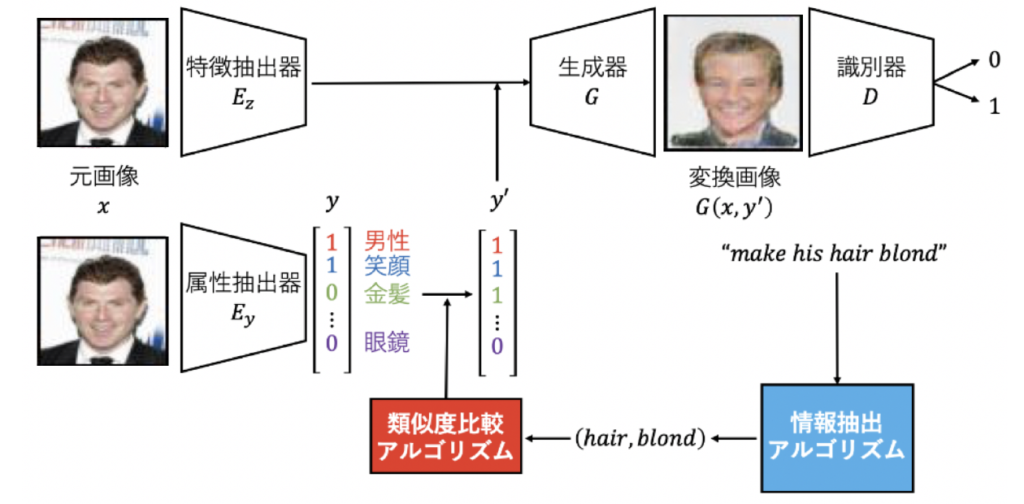
自然言語指示文による物体画像の属性変換
画像編集ソフトウェアの出現により,画像編集は活発に行われるようになった.これによってわずかな形状や色の調整などの単純な画像編集は容易となったが,人間の顔などの複雑な物体の画像を自然に編集するには依然として高度な技術が必要となる.本研究では,人間の顔画像に着目し,その属性を,英語の指示文のみを条件として変換することを目的とする.自然言語の指示文を条件とした顔画像の属性変化に基づく画像変換という問題設定を評価する評価指標を新たに設け,提案手法の評価を行う.
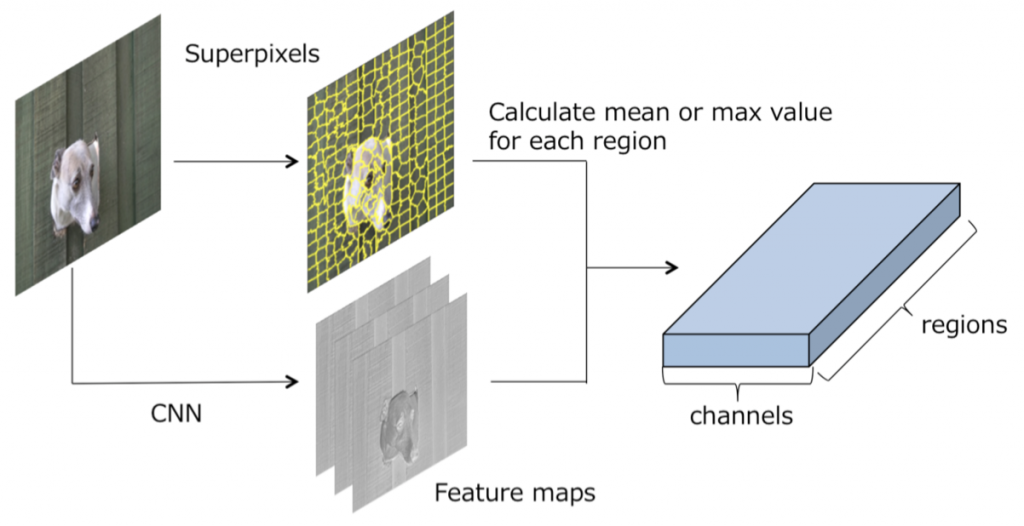
Segmentation のためのスーパーピクセル上でのGraph Convolutional Neural Networks
CNNを用いた画像領域分割の欠点として,プーリング層によるダウンサンプリングが原因で空間的な情報が欠落してしまい物体の輪郭付近での領域分割精度が低下する点があった.そこで,プーリングによる情報の欠落を防ぐ別のアプローチとして,スーパーピクセル上でのグラフ畳み込み(Graph Convolution)を提案した.また,グラフ畳み込みの拡張として,より効果的に受容野を広げるDilated Graph Convolutionを提案した. HKU-ISデータセットを用いた領域分割の課題において,提案手法が同一構成の従来のCNNを上回る性能を達成した.
CNN分類器を用いた画像識別における顕著性マップ生成
一般的に画像をCNN に入力し特定の出力が得られた場合に,なぜそのような出力が得られたかを説明することは難しい.本研究では,Generative Adversarial Networksの枠組みを応用した顕著性マップの生成手法を提案する.このシステムでは2つのニューラルネットワークを競わせながら学習する.1つ目のネットワークは,画像識別を行うように学習する.2つ目のネットワークは,ある画像が1つ目のネットワークに入力されてうまく画像識別ができる場合に,この画像には似ているが1つ目のネットワークに入力した場合に間違った結果を出力するような画像を生成するように学習する.2つ目のネットワークがこのような画像を効率的に生成するためには,1つ目のネットワークの画像識別において大切な画像領域を大きく変化させた画像を生成すれば良い.このような学習を行うことで,画像識別において重要な画像領域が明示的に出力可能となるため,これを顕著性マップとして捉えることができる.
GANによるカラー調整と画像補完の同時実行
本研究では,カラー調整と画像補完で自然な貼り付け合成を行う問題を解決するために,コンテキストを考慮したカラー調整を行いつつ画像補完を行う手法を提案する.挿入するオブジェクト画像を明示的に補完領域に出現させるようにするため,コンテキストを考慮した補完にCNNとGenerative Adversarial Network (GAN)を利用し,背景画像全体からコンテキストに関する特徴を抽出する.さらにそのコンテキストの特徴を,画像補完のためだけでなく,カラー調整にも利用することで,コンテキストを考慮したカラー調整を行う.このようにして,カラー調整と画像補完の課題を同時に解決するネットワークを実現する.

