Pioneering new domains in pattern recognition and image sensing
Deep learning is becoming indispensable in image pattern recognition. Our laboratory uses existing deep learning models, promotes research to further improve recognition accuracy and realize highly human-compatible recognition systems, such as new architecture and learning methods, and attempts to visualize and understand the internals of these . In addition, we pursue new image sensing methods, including image measurement, recognition and generation, with the aim of pioneering these domains.
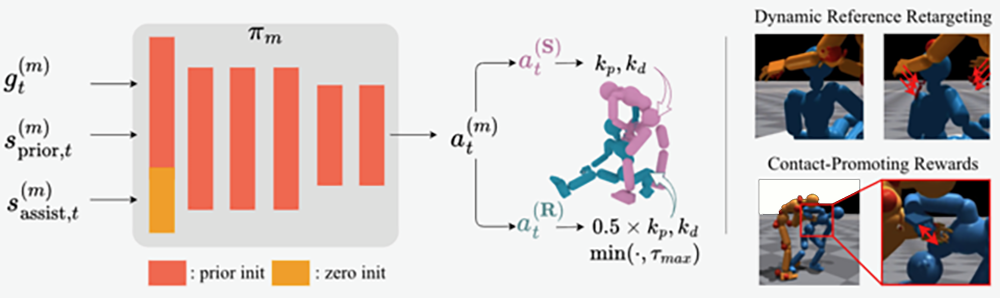
Learning to Assist: Physics-Grounded Human-Human Control via Multi-Agent Reinforcement Learning
(Accepted for CVPR 2026)
Humanoid robotics holds strong potential for caregiving and assistive applications, yet existing motion tracking methods are largely limited to contact-less interactions or isolated movements, making them ill-suited for assistive scenarios that demand continuous awareness of and rapid adaptation to a human partner. We formulate the imitation of closely interacting, force-exchanging human–human motion sequences as a **multi-agent reinforcement learning problem**, jointly training partner-aware policies for both the supporter and recipient agents in a physics simulator. To make this tractable, we introduce **partner policies initialization** that transfers priors from single-human motion-tracking controllers, **dynamic reference retargeting** that adapts the assistant’s reference motion to the recipient’s real-time pose, and a **contact-promoting reward** that encourages physically meaningful support. AssistMimic is the first method capable of successfully tracking assistive interaction motions on established benchmarks (Inter-X, HHI-Assist), demonstrating the benefits of a multi-agent RL formulation for physically grounded and socially aware humanoid control.
Project page: https://yutoshibata07.github.io/AssistMimic-projectpage/
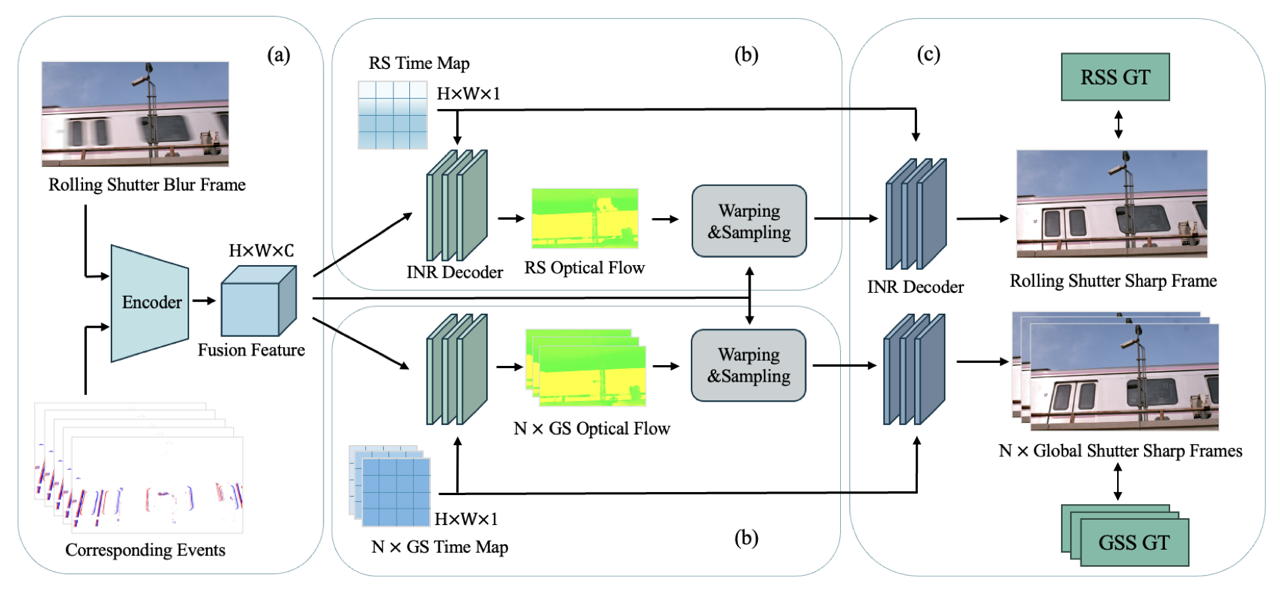
EMARS: Event-based Motion-Aware Correction, Deblurring and Interpolation of Rolling Shutter Images
(Accepted for the IEEE ICIP 2026)
Rolling Shutter (RS) CMOS sensors are cost-effective but introduce severe geometric distortions and motion blur under high-speed motion, limiting their use in critical vision applications. Event cameras provide crucial motion cues to address these artifacts, yet existing unified methods using Implicit Neural Representation (INR) often suffer from residual blur and detail loss caused by information loss during implicit compression. We propose a novel framework that explicitly utilizes time-conditional optical flow as the central kinematic constraint to jointly perform RS correction, deblurring, and frame interpolation. Our model extracts optical flow based on query time and introduces a Flow-Constrained INR to enforce geometric consistency, ensuring the INR learns a physically consistent motion trajectory. Experiments demonstrate state-of-the-art PSNR and SSIM scores across all temporal upsampling factors.
Listening without Looking: Modality Bias in Audio-Visual Captioning
(Accepted for the IEEE ICIP 2026)
Audio-visual captioning aims to generate holistic scene descriptions by jointly modeling sound and vision. While recent methods have improved performance through sophisticated modality fusion, it remains unclear to what extent the two modalities are complementary and how robust these models are when one is degraded. We conduct systematic modality robustness tests on LAVCap, a state-of-the-art model, by selectively suppressing or corrupting the audio or visual streams to quantify sensitivity and complementarity, revealing a pronounced bias toward the audio stream. To evaluate how balanced these models are, we augment AudioCaps with annotations jointly describing both streams, yielding the AudioVisualCaps dataset. Our experiments show that LAVCap trained on

4D Reconstruction from Sparse Dynamic Cameras
(Accepted for CVPR 2026 Workshop 4DV: 2nd Workshop on 4D Vision: Modeling the Dynamic World)
Dynamic 3D (4D) reconstruction from a monocular dynamic camera has recently advanced but remains fundamentally limited by depth ambiguity. We focus on a sparse dynamic camera setup, in which a handful of independently moving cameras capture the same subjects, keeping capture costs low while introducing multi-view constraints—practical for real-world video production such as sports, concerts, and TV shows. Since naive extensions of existing methods fail to resolve complex spatiotemporal inconsistencies, we propose a 3D track initialization method integrating inter-camera feature matching with intra-camera point tracking, together with a noise-robust depth-ordering regularization loss and a spatiotemporally diverse batch sampling strategy. We also introduce LetCamsGo, a new real-world video dataset for this task, on which our framework significantly improves 4D reconstruction quality in dynamic regions.

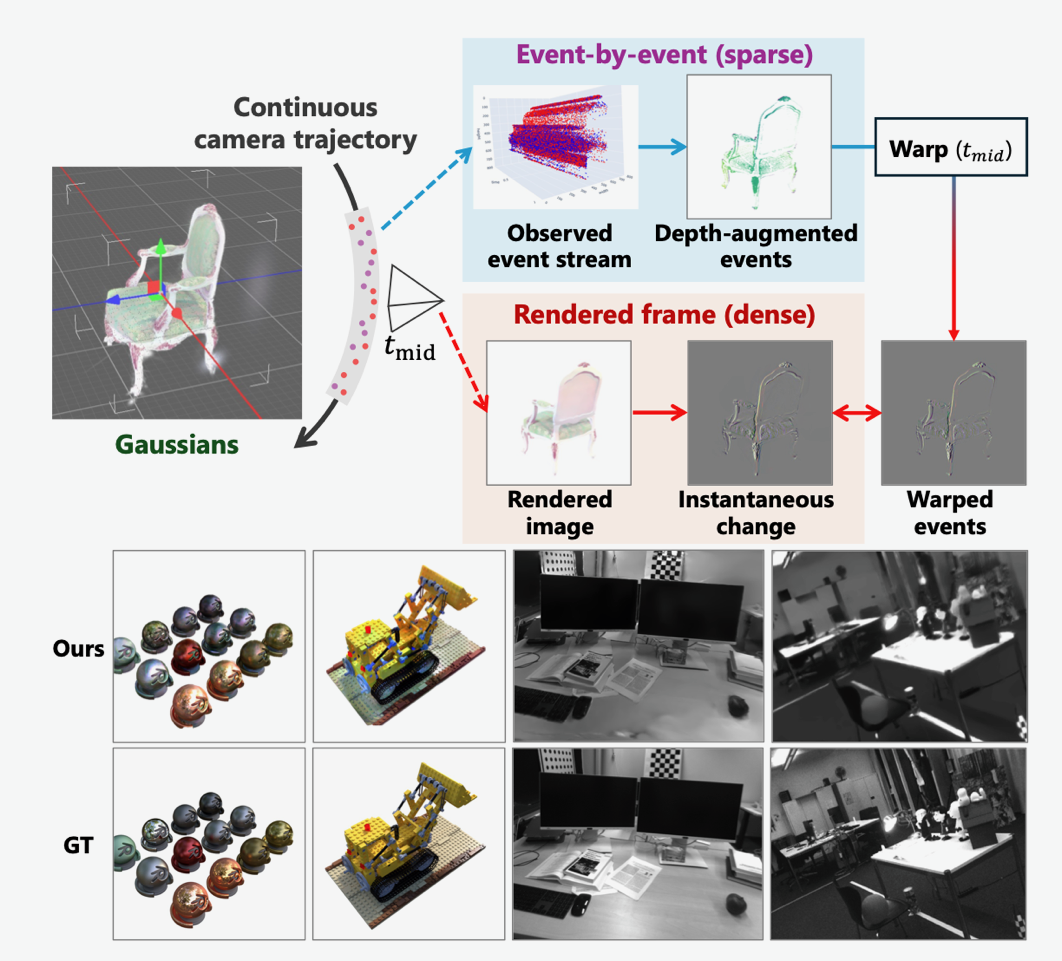
Geometric-Photometric Event-based 3D Gaussian Ray Tracing (GPERT)
(Accepted as a Highlight at CVPR 2026)
We propose GPERT, the first event-based 3D Gaussian Splatting framework that fully exploits the spatially sparse yet temporally dense nature of event data. GPERT decouples rendering into two complementary branches — event-by-event geometry (depth) rendering via ray tracing and snapshot-based radiance rendering — and connects them through the Image of Warped Events, thereby resolving the accuracy–temporal-resolution trade-off of prior event-based 3DGS methods. Without any pretrained models or COLMAP-based initialization, GPERT achieves state-of-the-art performance on real-world datasets, the fastest training time among compared methods, and sharper reconstruction along scene edges.
Authors: Kai Kohyama, Yoshimitsu Aoki (Keio University), Guillermo Gallego (TU Berlin et al.), Shintaro Shiba (Keio University / The University of Tokyo)
Project: https://e3ai.github.io/gpert/
Code: https://github.com/e3ai/gpert
Paper: https://arxiv.org/abs/2512.18640
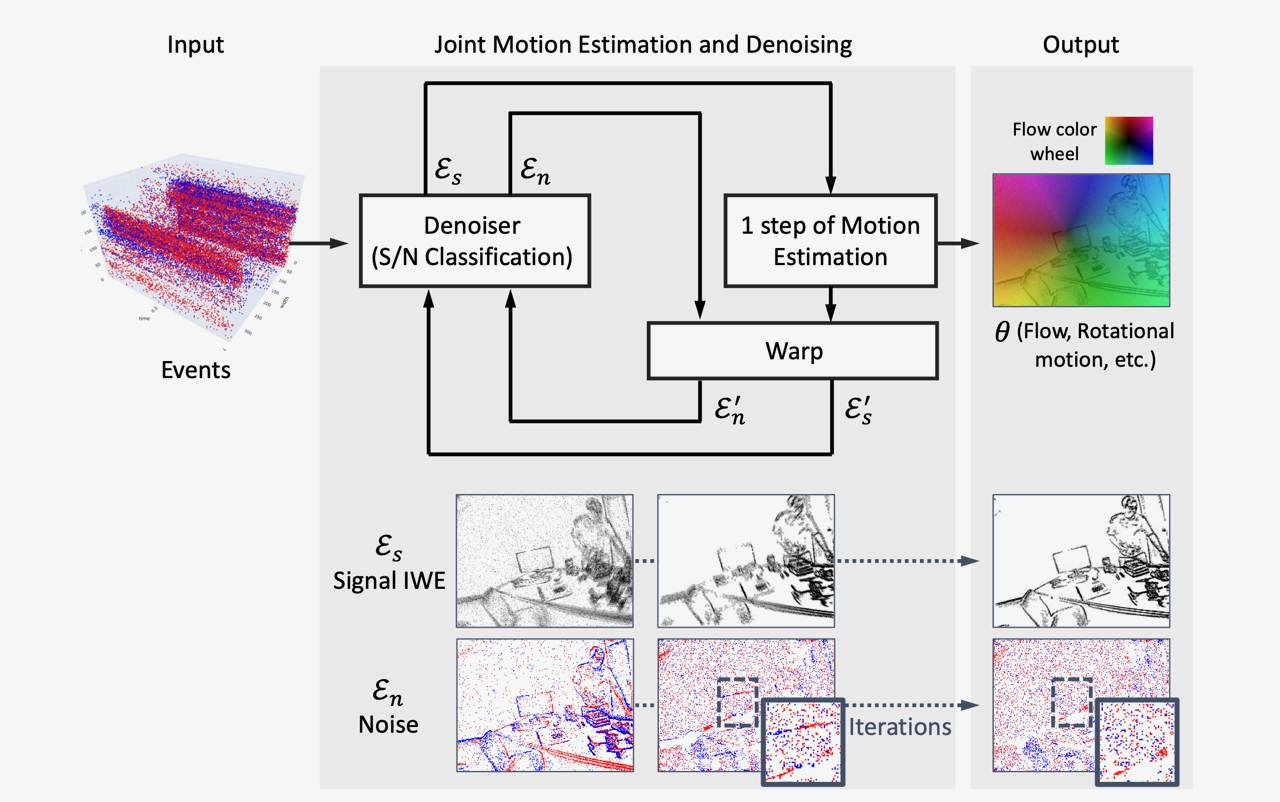
Simultaneous Motion And Noise Estimation with Event Cameras
(ICCV2025)
This paper introduces the first framework that jointly estimates motion (e.g., ego‑motion, optical flow) and noise directly from raw events. Unlike prior pipelines that denoise first and estimate motion later, ESMD treats motion as intrinsic to event data and solves both tasks together; the paper has been accepted to ICCV 2025.
Method‑wise, ESMD extends the Contrast Maximization (CMax) framework by quantifying each event’s contribution to image contrast, and iteratively optimizes event‑level signal/noise assignment along with motion parameters. The framework is flexible—it can replace the one‑step CMax motion estimation with any motion estimator, including deep neural networks.
On benchmarks, ESMD achieves state‑of‑the‑art performance on E‑MLB and competitive results on DND21. It also improves the robustness of both ego‑motion and optical‑flow estimation, and enhances intensity reconstruction quality (e.g., with E2VID/EVILIP).
Paper: https://arxiv.org/abs/2504.04029
Code: https://github.com/tub-rip/ESMD
Video: https://www.youtube.com/watch?v=iJZsIEWinXk
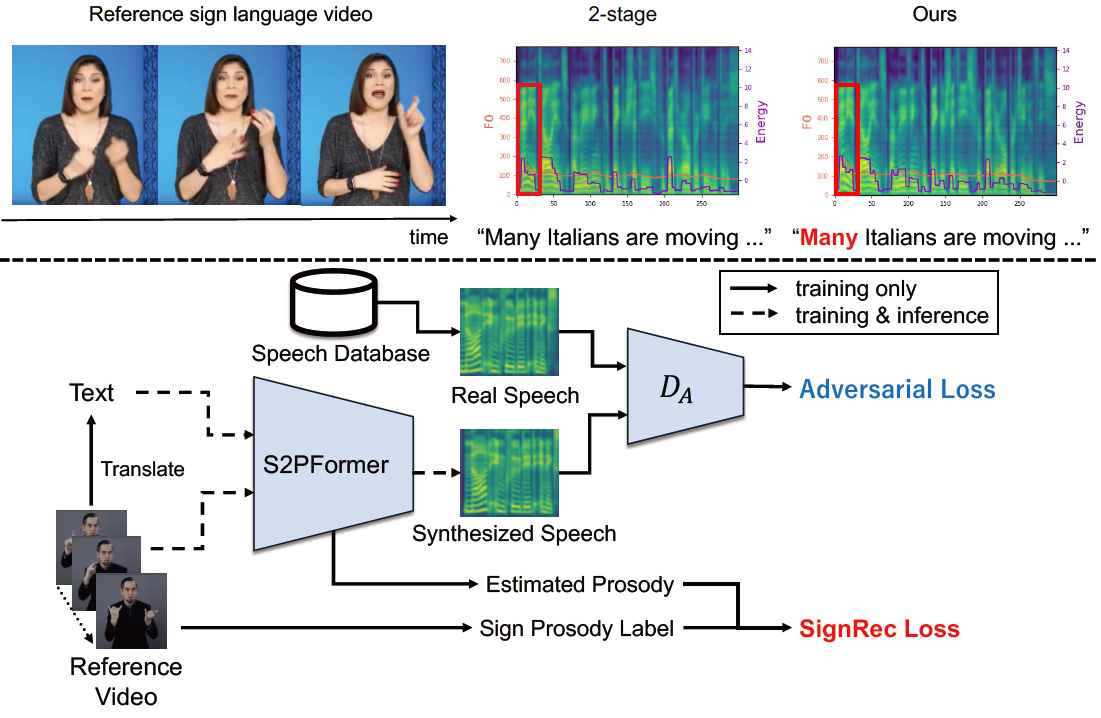
Sign-to-Speech Prosody Transfer(ICPR2026)
Sign language is a vital communication tool for the hearing-impaired, yet existing sign-to-text-to-speech systems lose important prosodic cues such as emphasis and intonation. To address this, we propose a new task, Sign-to-Speech Prosody Transfer, which directly conveys prosodic nuances from sign gestures to synthesized speech. Our model, S2PFormer, learns from unpaired data and uses cross-attention between body joint and text information to capture fine-grained prosody. Experiments show that S2PFormer produces speech that better reflects the natural rhythm of sign language, paving the way for more expressive and accessible communication.
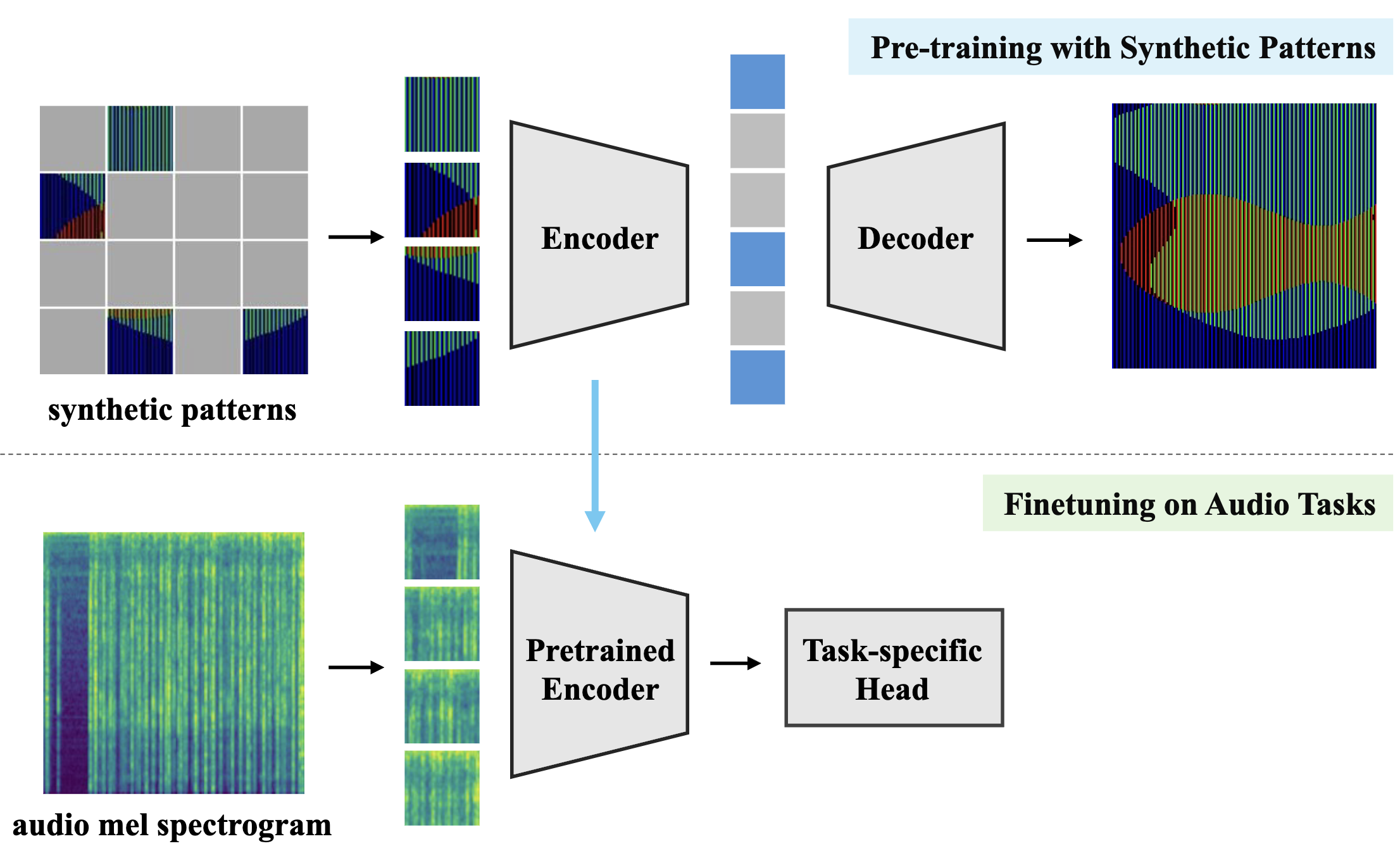
Pre-training with Synthetic Patterns for Audio
In this paper, we propose to pre-train audio encoders using synthetic patterns instead of real audio data. Our proposed framework consists of two key elements. The first one is Masked Autoencoder (MAE), a self-supervised learning framework that learns from reconstructing data from randomly masked counterparts. MAEs tend to focus on low-level information such as visual patterns and regularities within data. Therefore, it is unimportant what is portrayed in the input, whether it be images, audio mel-spectrograms, or even synthetic patterns. This leads to the second key element, which is synthetic data. Synthetic data, unlike real audio, is free from privacy and licensing infringement issues. By combining MAEs and synthetic patterns, our framework enables the model to learn generalized feature representations without real data, while addressing the issues related to real audio. To evaluate the efficacy of our framework, we conduct extensive experiments across a total of 13 audio tasks and 17 synthetic datasets. The experiments provide insights into which types of synthetic patterns are effective for audio. Our results demonstrate that our framework achieves performance comparable to models pre-trained on AudioSet-2M and partially outperforms image-based pre-training methods.
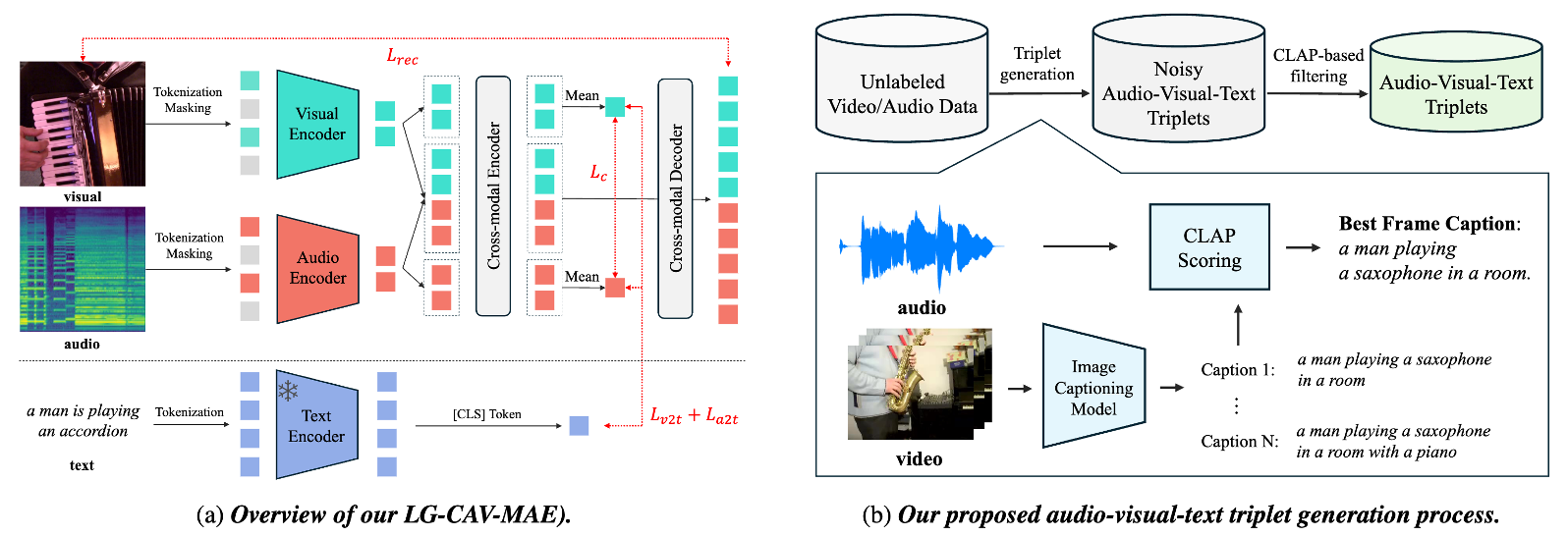
Language-Guided Contrastive Audio-Visual Masked Autoencoder with Automatically Generated Audio-Visual-Text Triplets from Videos
In this paper, we propose Language-Guided Contrastive Audio- Visual Masked Autoencoders (LG-CAV-MAE) to improve audio-visual representation learning. LG-CAV-MAE integrates a pretrained text encoder into contrastive audio-visual masked autoencoders, enabling the model to learn across audio, visual and text modalities. To train LG-CAV-MAE, we introduce an automatic method to generate audio-visual-text triplets from unlabeled videos. We first generate frame-level captions using an image captioning model and then apply CLAP-based filtering to ensure strong alignment between audio and captions. This approach yields high-quality audio-visual-text triplets without requiring manual annotations. We evaluate LG-CAV-MAE on audio-visual retrieval tasks, as well as an audio-visual classification task. Our method significantly outperforms existing approaches, achieving up to a 5.6% improvement in recall@10 for retrieval tasks and a 3.2% improvement for the classification task.
Text-guided Synthetic Geometric Augmentation for Zero-shot 3D Understanding
Zero-shot recognition models require extensive training data for generalization. However, in zero-shot 3D classification, collecting 3D data and captions is costly and labor-intensive, posing a significant barrier compared to 2D vision. Recent advances in generative models have achieved unprecedented realism in synthetic data production, and recent research shows the potential for using generated data as training data. Here, naturally raising the question: Can synthetic 3D data generated by generative models be used as expanding limited 3D datasets? In response, we present a synthetic 3D dataset expansion method, Text-guided Geometric Augmentation (TeGA). TeGA is tailored for language-image-3D pretraining, which achieves SoTA in zero-shot 3D classification, and uses a generative text-to-3D model to enhance and extend limited 3D datasets. Specifically, we automatically generate text-guided synthetic 3D data and introduce a consistency filtering strategy to discard noisy samples where semantics and geometric shapes do not match with text. In the experiment to double the original dataset size using TeGA, our approach demonstrates improvements over the baselines, achieving zero-shot performance gains of 3.0% on Objaverse-LVIS, 4.6% on ScanObjectNN, and 8.7% on ModelNet40.
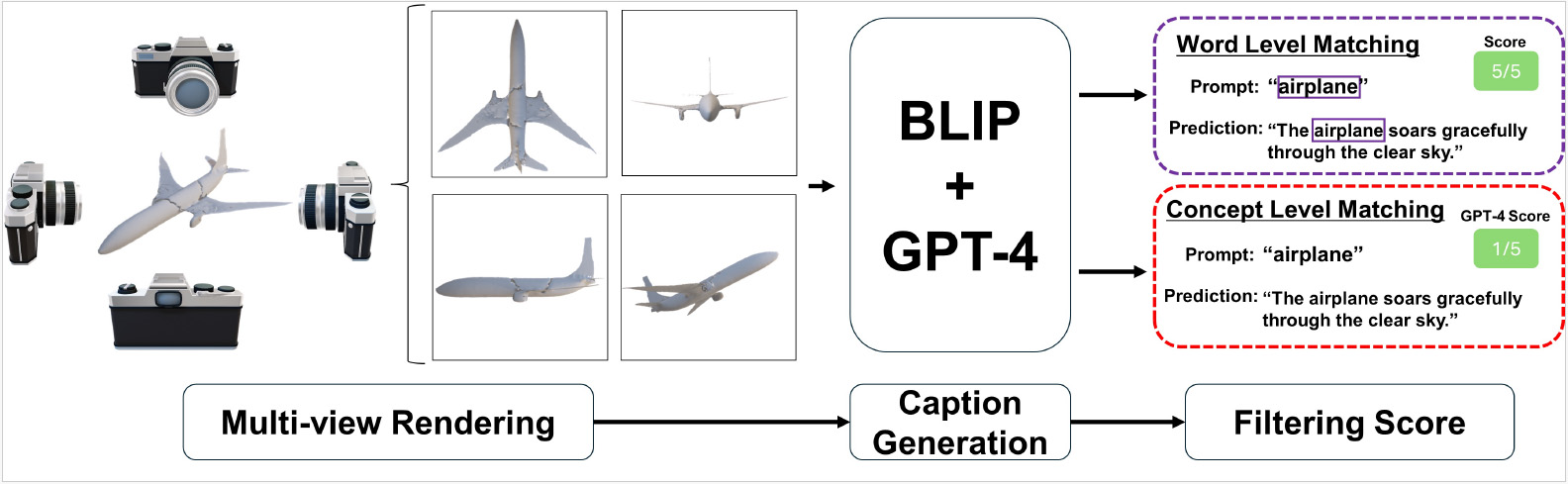
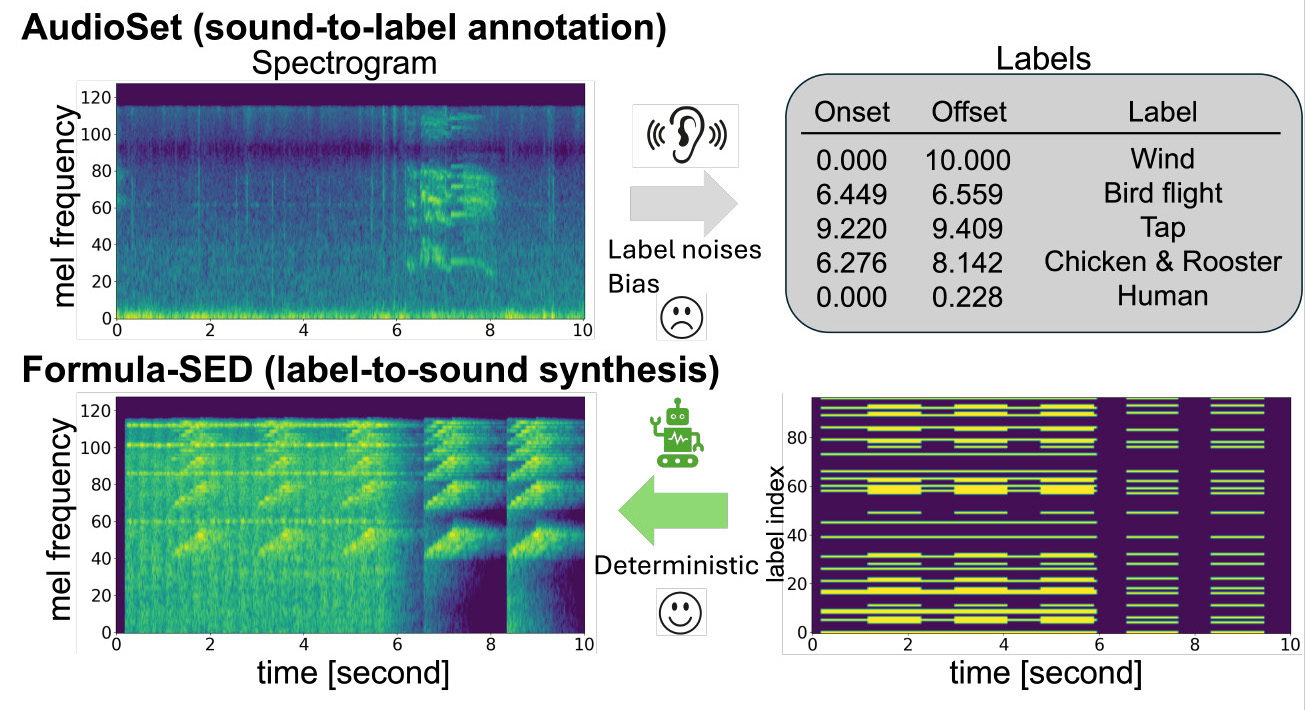
Formula-Supervised Sound Event Detection: Pre-Training Without Real Data
Conventional approaches to Sound Event Detection (SED) face challenges due to limited labeled data and noisy, subjective annotations. We propose a novel pre-training framework, Formula-SED, that generates synthetic acoustic data purely from mathematical formulas. By using synthesis parameters as ground truth, our method enables large-scale, noise-free pre-training. Experiments on the DESED dataset show that models pre-trained with Formula-SED achieve higher accuracy and faster convergence.
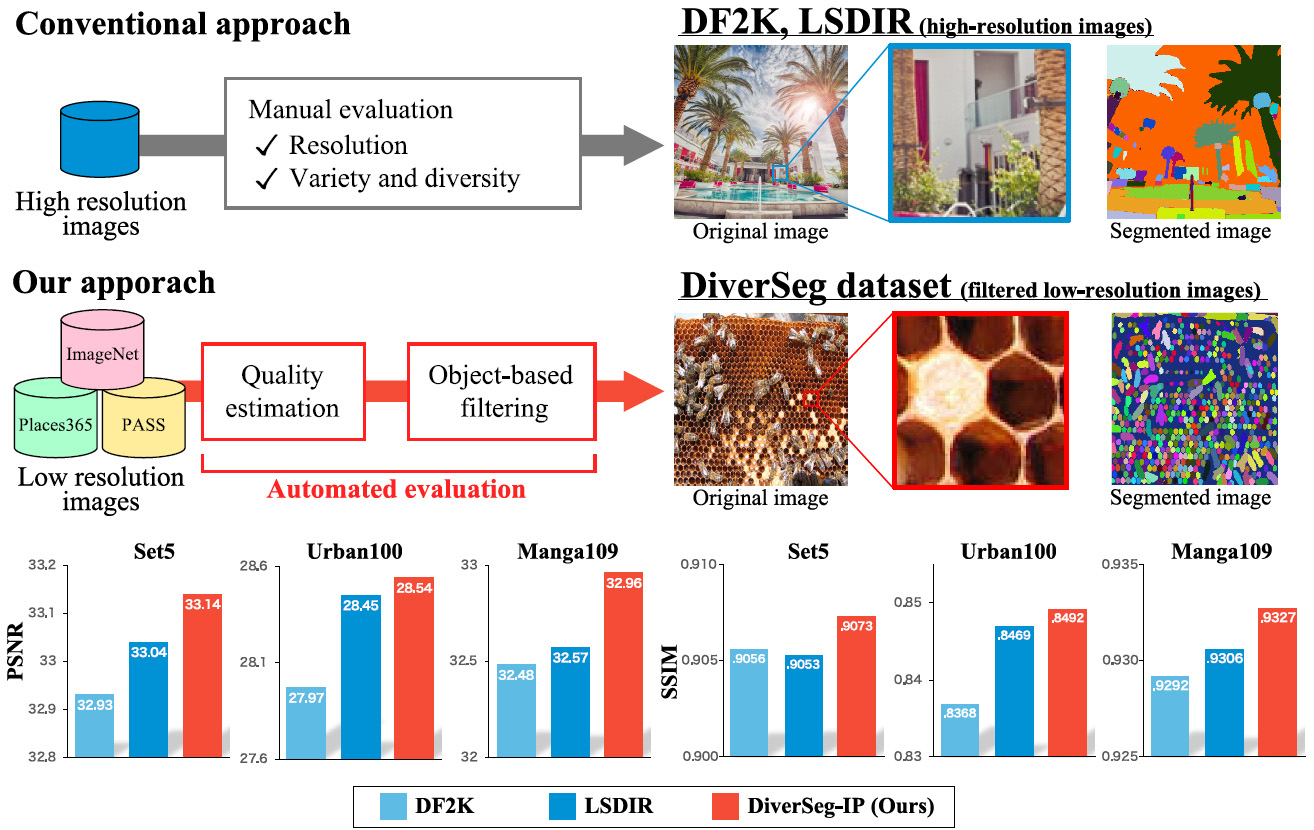
Rethinking Image Super-Resolution from Training Data Perspectives
In this work, we investigate the understudied effect of the training data used for image super-resolution (SR). Most commonly, novel SR methods are developed and benchmarked on common training datasets such as DIV2K and DF2K. However, we investigate and rethink the training data from the perspectives of diversity and quality, thereby addressing the question of “How important is SR training for SR models?”. To this end, we propose an automated image evaluation pipeline. With this, we stratify existing high-resolution image datasets and larger-scale image datasets such as ImageNet and PASS to compare their performances. We find that datasets with (i) low compression artifacts, (ii) high within-image diversity as judged by the number of different objects, and (iii) a large number of images from ImageNet or PASS all positively affect SR performance.
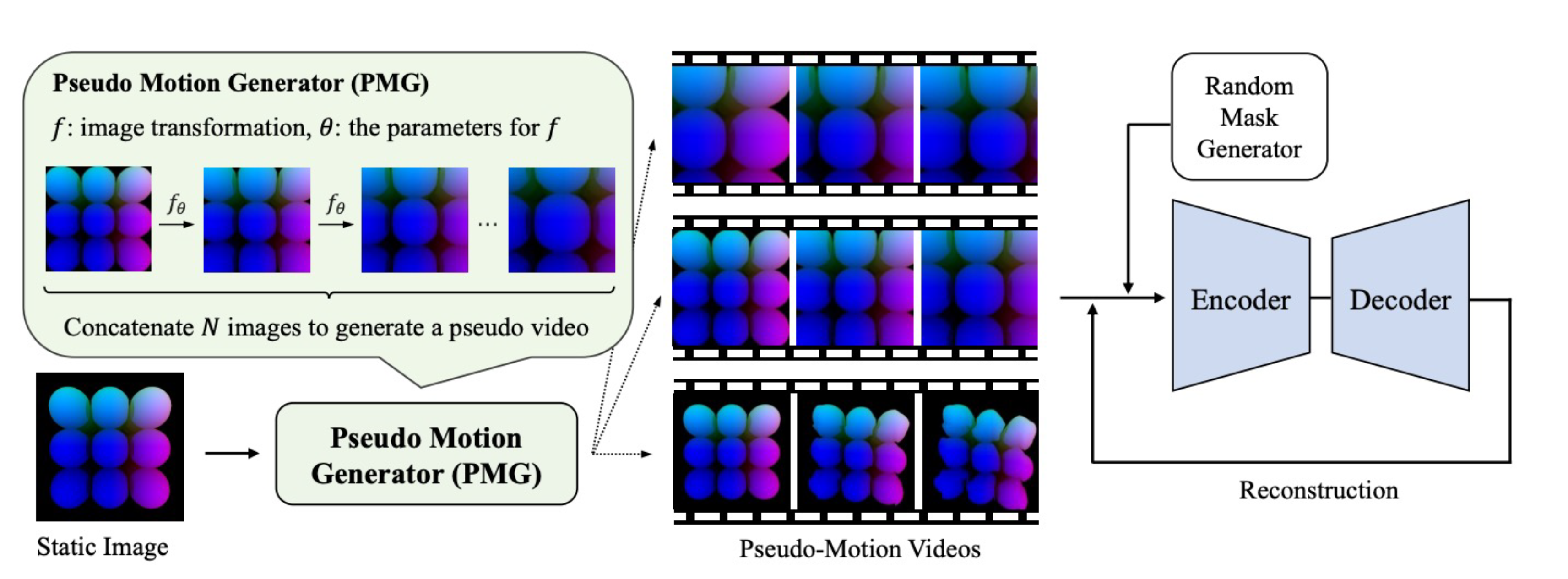
Data Collection-free Masked Video Modeling
Pre-training video transformers generally requires a large amount of data, presenting significant challenges in terms of data collection costs and concerns related to privacy, licensing, and inherent biases. Synthesizing data is one of the promising ways to solve these issues, yet pre-training solely on synthetic data has its own challenges. In this paper, we introduce an effective self-supervised learning framework for videos that leverages readily available and less costly static images. Specifically, we define the Pseudo Motion Generator (PMG) module that recursively applies image transformations to generate pseudo-motion videos from images. These pseudo-motion videos are then leveraged in masked video modeling. Our approach is applicable to synthetic images as well, thus entirely freeing video pre-training from data collection costs and other concerns in real data. Through experiments in action recognition tasks, we demonstrate that this framework allows effective learning of spatio-temporal features through pseudo-motion videos, significantly improving over existing methods which also use static images and partially outperforming those using both real and synthetic videos. These results uncover fragments of what video transformers learn through masked video modeling.
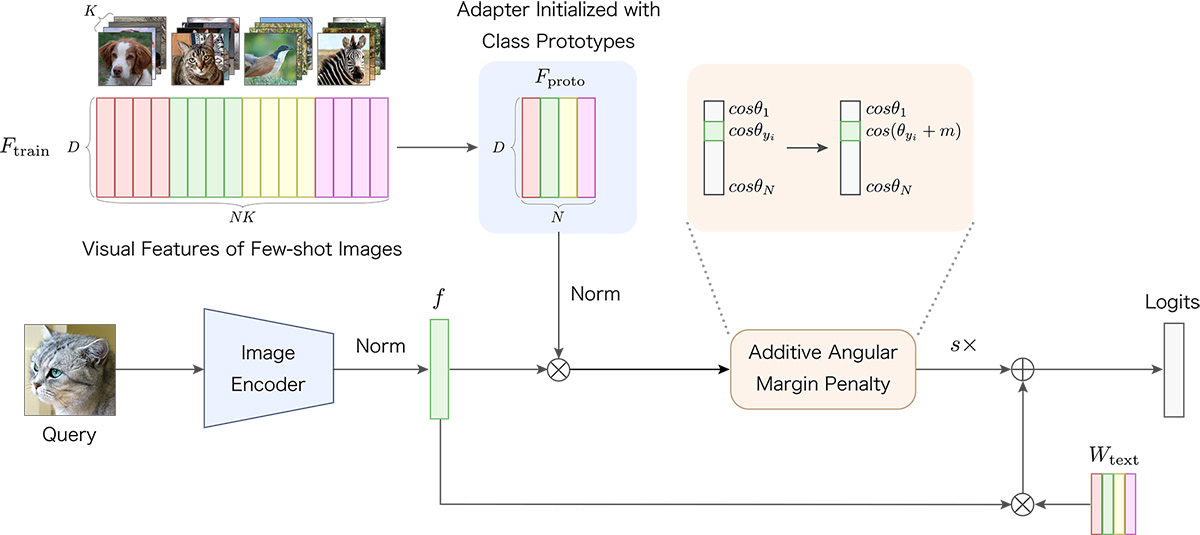
Proto-Adapter: Efficient Training-Free CLIP-Adapter for Few-Shot Image Classification
Image recognition through few-shot learning becomes essential in applications where acquiring large amounts of data is challenging. One of the large vision-language models, CLIP, can recognize images of any class in a zero-shot manner. However, there is room for improvement in its performance on downstream tasks. We propose a novel method called Proto-Adapter, which adapts CLIP to downstream tasks using a small amount of training data. The proposed method constructs a lightweight adapter using prototype representations of each class, significantly enhancing performance on downstream tasks with minimal additional computational cost. We demonstrate the effectiveness of our method through experiments using eleven image recognition benchmarks.
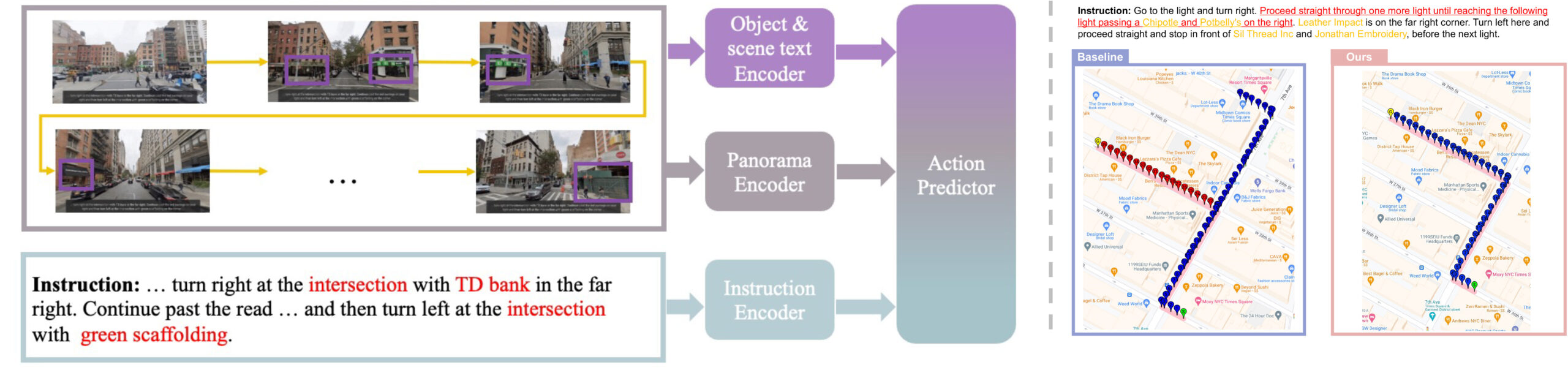
Guided by the Way: The Role of On-the-route Objects and Scene Text in Enhancing Outdoor Navigation
https://2024.ieee-icra.org
In outdoor environments, Vision-and-Language Navigation (VLN) requires an agent to rely on multi-modal cues from real-world urban environments and natural language instructions. While existing outdoor VLN models predict actions using a combination of panorama and instruction features, this approach ignores objects in the environment and learns data bias to fail navigation. According to our preliminary findings, most instances of navigation failure in previous models were due to turning or stopping at the wrong place. In contrast, humans intuitively frequently use identifiable objects or store names as reference landmarks, ensuring accurate turns and stops, especially in unfamiliar places. To address this insight gap, we propose an Object-Attention VLN (OAVLN) model that helps the agent focus on relevant objects during training and understand the environment better. Our model outperforms previous methods in all evaluation metrics under both seen and unseen scenarios on two existing benchmark datasets, Touchdown and map2seq.
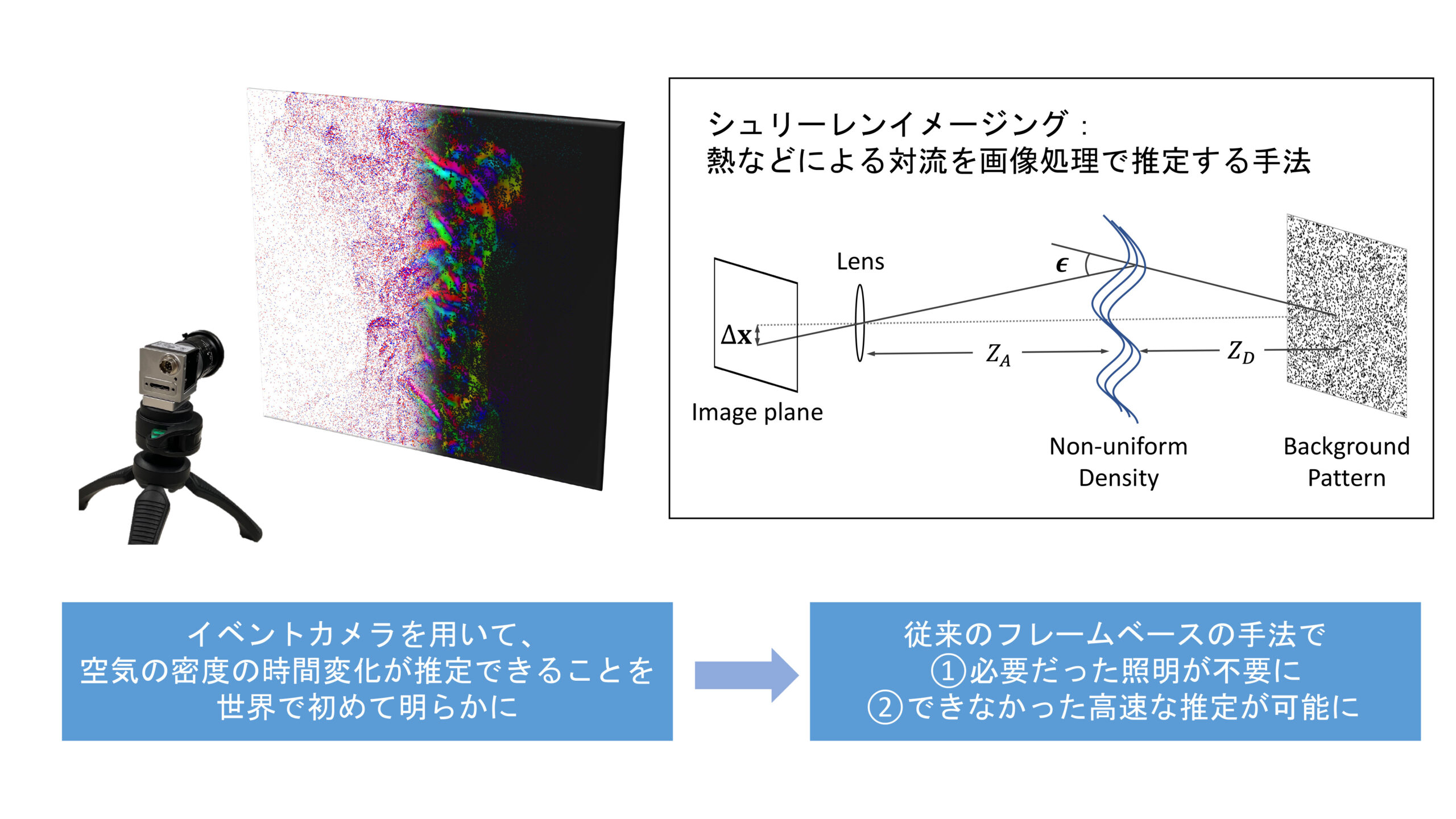
Non-invasive estimation of air convection by Schlieren imaging technique using event cameras
https://ieeexplore.ieee.org/document/10301562
Schlieren imaging is a technique for visualising density changes in transparent media such as air using a camera. Event cameras, which record only changes, are characterised by high speed and high dynamic range compared to conventional frame cameras. These characteristics were utilised to develop the world’s first Schlieren imaging technique using an event camera. It was theoretically and experimentally demonstrated that temporal changes in density in thermal convection of air, for example, can be estimated. Furthermore, it was shown that the characteristics of the event camera make it possible to perform slow-motion analysis without the need for lighting equipment, which is necessary for conventional frame-based imaging.
Video:https://www.youtube.com/watch?v=Ev52n8KgxIU
Code:https://github.com/tub-rip/event_based_bos
Paper:https://ieeexplore.ieee.org/document/10301562
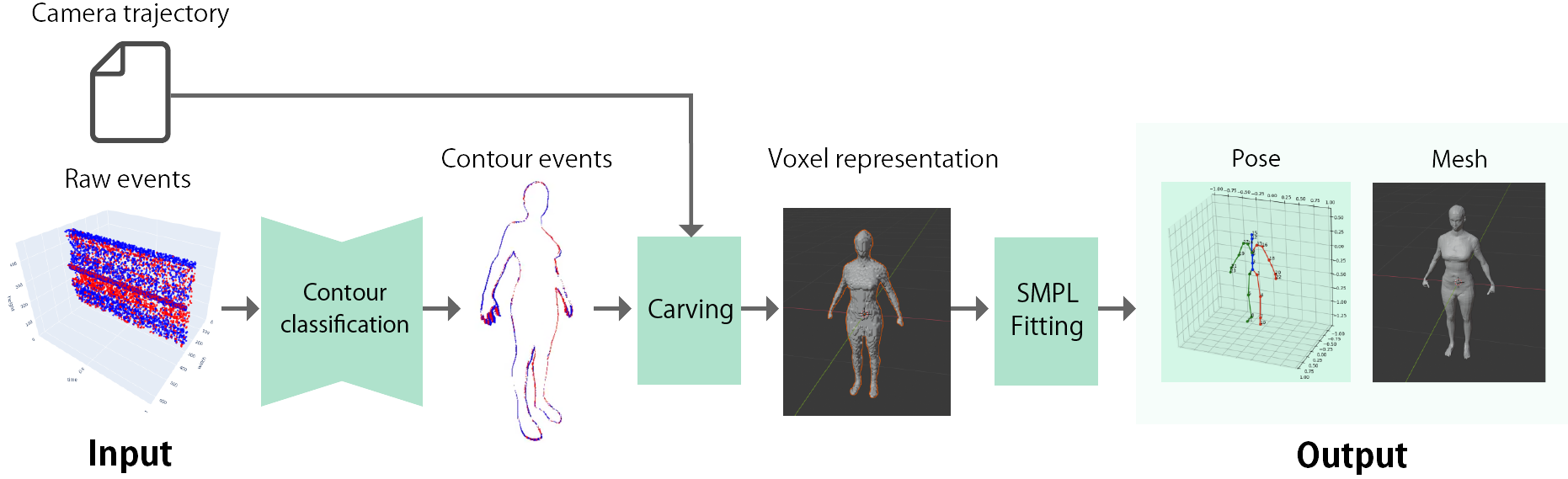
3D Human Scan With A Moving Event Camera
Project page: https://florpeng.github.io/event-based-human-scan/
Arxiv: https://arxiv.org/abs/2404.08504
Conventional frame cameras are limited by their temporal resolution and dynamic range, which imposes constraints in real-world application setups. Therefore we proposed a novel event-based method to estimate human poses and recover human meshes from solely event data.
The proposed method achieved higher accuracy than frame-based methods and performed effectively in the challenging situation where other frame-based methods suffer from motion blur.
Building a large dataset for image recognition for retail products
We have created a large dataset for image recognition of a retail store shelf. The annotation cost of retail shelves is extremely high, due to the nature that a large number of products exist in one image at the same time. Therefore, we created a large dataset of 200 classes and 100,000 images by creating photorealistic images of retail shelves using 3DCG and automatically annotating them based on the 3D coordinate data of the objects.
The dataset can be downloaded from the linked page (use for research purposes only).

https://yukiitoh0519.github.io/CG-Retail-Shelves-Dataset/
MaskDiffusion: Exploiting Pre-trained Diffusion Models for Semantic Segmentation
MaskDiffusion is an innovative approach that leverages pretrained frozen Stable Diffusion to achieve open-vocabulary semantic segmentation without the need for additional training or annotation, leading to improved performance compared to similar methods. We demonstrate the superior performance of MaskDiffusion in handling open vocabularies, including fine-grained and proper noun-based categories, thus expanding the scope of segmentation applications. MaskDiffusion shows significant qualitative and quantitative improvements in contrast to other comparable unsupervised segmentation methods, i.e. on the Potsdam dataset (+10.5 mIoU compared to GEM) and COCO-Stuff (+14.8 mIoU compared to DiffSeg).
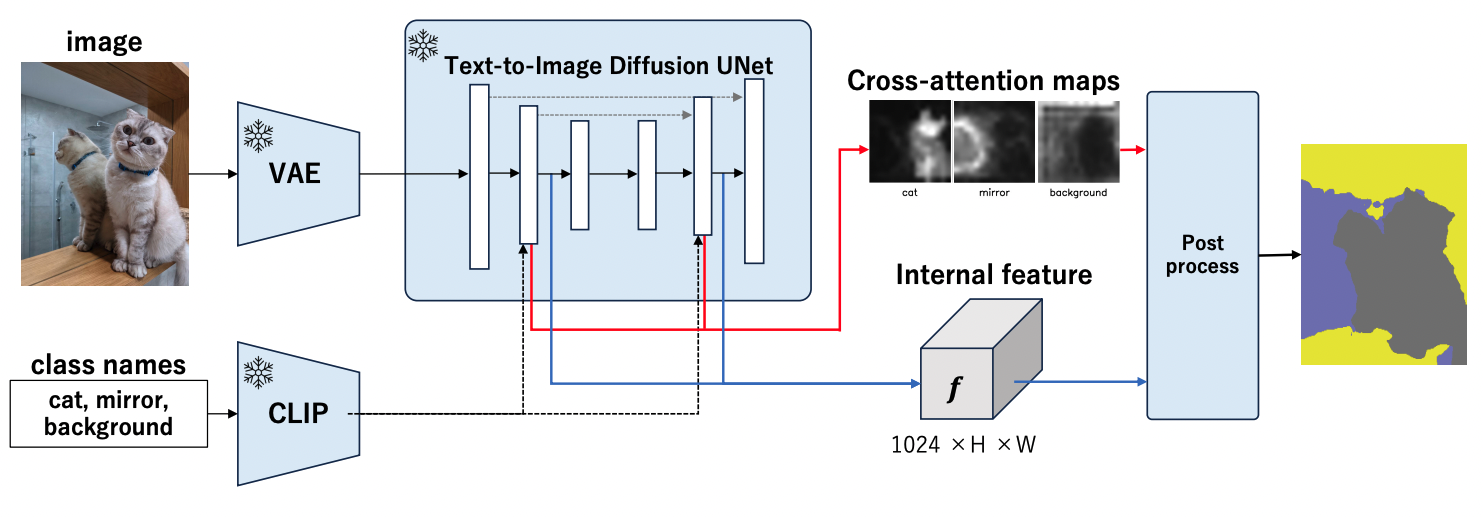
Arxiv: https://arxiv.org/abs/2403.11194
Code : https://github.com/Valkyrja3607/MaskDiffusion
TAG: Guidance-free Open-Vocabulary Semantic Segmentation
We propose a novel approach, TAG which achieves Training, Annotation, and Guidance-free open-vocabulary semantic segmentation. TAG utilizes pre-trained models such as CLIP and DINO to segment images into meaningful categories without additional training or dense annotations. It retrieves class labels from an external database, providing flexibility to adapt to new scenarios. TAG achieves state-of-the-art results on PascalVOC, PascalContext and ADE20K for open-vocabulary segmentation without given class names, i.e. improvement of +15.3 mIoU on PascalVOC.

Arxiv: https://arxiv.org/abs/2403.11197
Code : https://github.com/Valkyrja3607/TAG
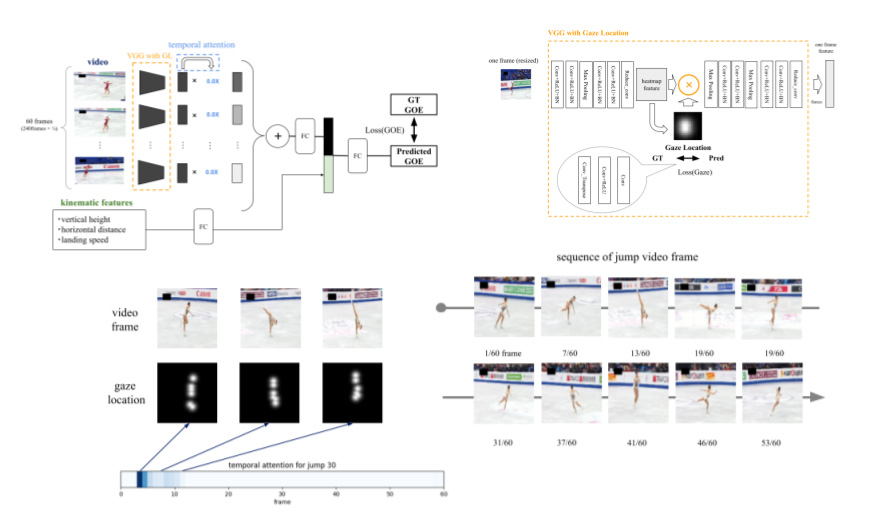
Assessing the quality of figure skating jumps using the expert’s gaze location
Proposed a prediction model for jump performance (Grade of Execution score) using kinematic features obtained from broadcast videos and tracking systems. The proposed method improved accuracy from the baseline model by weighting information in the spatial direction due to the human judges’ and skaters’ gaze location to extract features that affect jump performance from the broadcast video in addition to the weighting of temporal information.
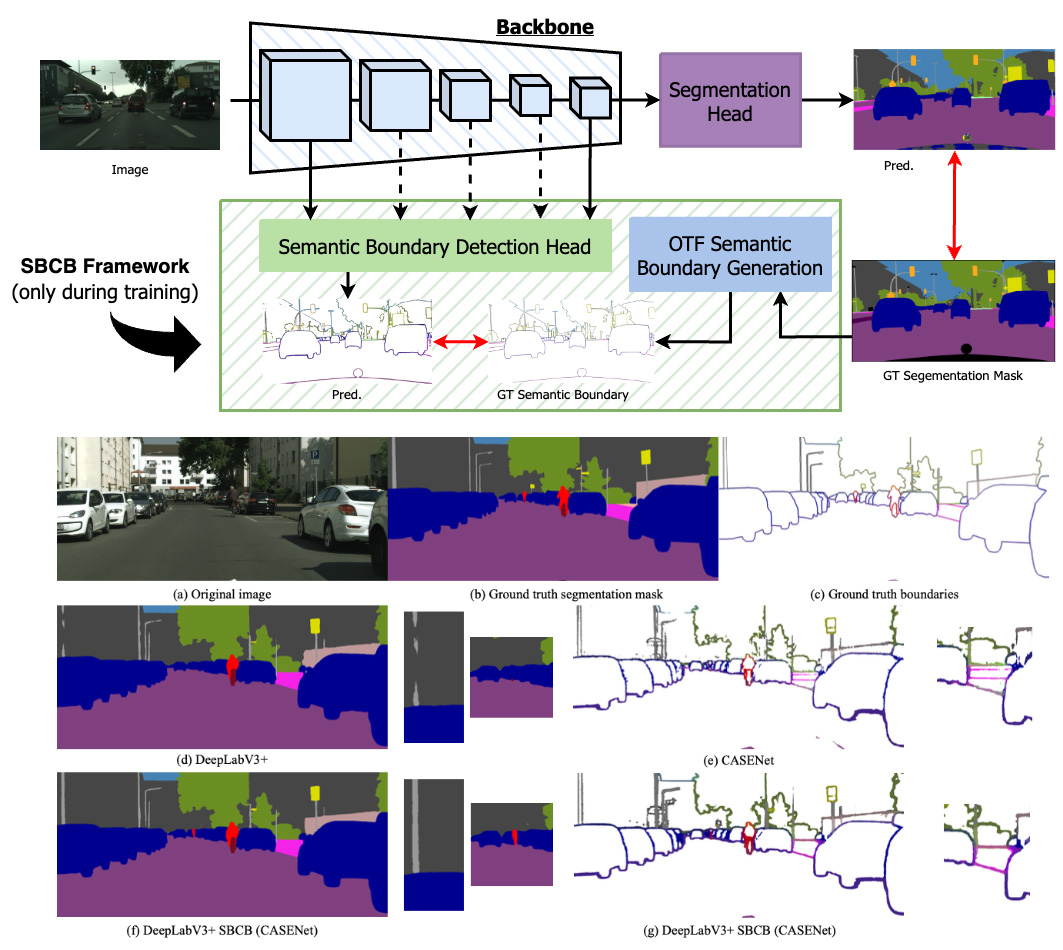
Boosting Semantic Segmentation by Conditioning the Backbone with Semantic Boundaries
The Semantic Boundary Conditioned Backbone (SBCB) framework is introduced as an effective method for enhancing semantic segmentation performance, particularly at mask boundaries, while remaining compatible with diverse segmentation architectures. The framework integrates a semantic boundary detection (SBD) task using multi-scale features from the segmentation backbone, operating in conjunction with common semantic segmentation architectures. This approach achieves an average 1.2% IoU improvement and a 2.6% boundary F-score gain on Cityscapes dataset, enhancing both segmentation accuracy and boundary delineation. The SBCB framework adapts well to various backbones, including vision transformer models, showcasing its potential to advance semantic segmentation without introducing model complexity.
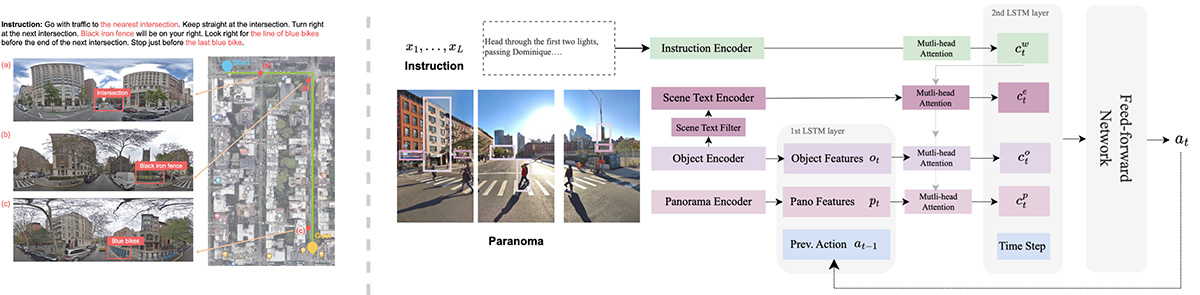
Boosting Outdoor Vision-and-Language Navigation with On-the-route Objects
Vision-and-Language Navigation (VLN) task aims to enable robots to navigate real-world environments using natural language instructions. In recent years, numerous VLN models have been proposed, which predict action sequences by combining instructions and panoramic features. However, these models often overlook specific semantics and object recognition. Preliminary experiments revealed that existing models do not sufficiently focus on object tokens. This trend contrasts with human behavior, as people typically rely on landmarks when navigating unfamiliar areas. To address this, our study introduces the Object-Attention VLN (OAVLN) model, designed to place emphasis on objects mentioned in navigation instructions and to enhance the agent’s environmental understanding. Experiments across multiple datasets have demonstrated the superiority of OAVLN, showcasing its ability to utilize objects as primary navigation landmarks and effectively guide agents.
Efficient Video Recognition via Informative Patch Selection
Video is much more expensive to process than images, while the information in each frame image in the same video is similar and so highly redundant. In this study, we propose a video recognition method that reduces the processing cost by excluding patches that have small temporal motion or change from the input. Since we obtain these temporal motion and change while decoding a compressed video, the overhead of calculating them is negligible. By applying the proposed method to a Transformer-based video model, we achieved a processing cost reduction of more than 70% with an accuracy drop of less than 1 point on action recognition task.

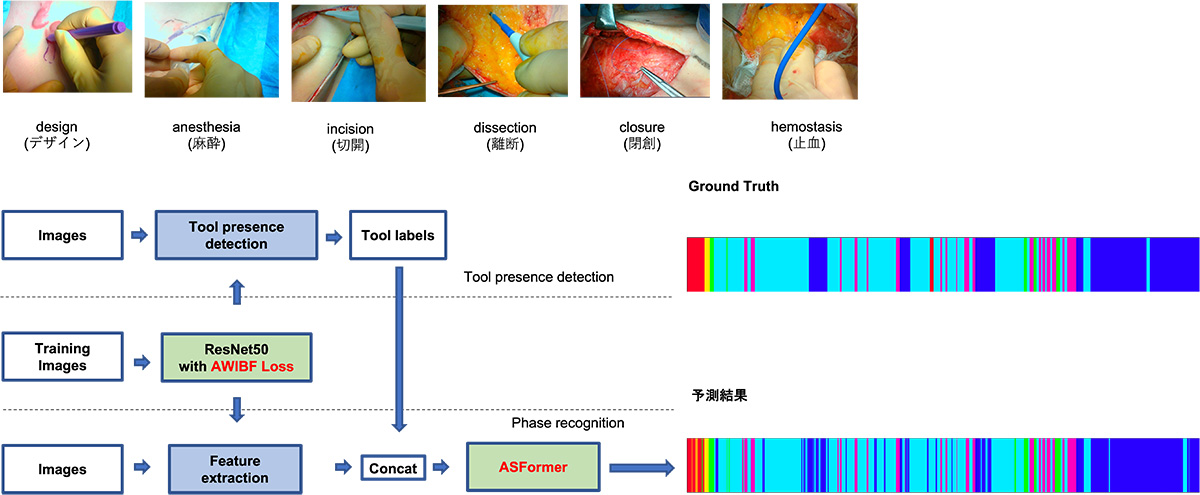
Surgical workflow recognition for effective use of plastic surgery video
In this study, we proposed a model for surgical workflow recognition in plastic surgery videos. Compared to endoscopic surgery, which has been studied in many surgical videos, plastic surgery videos have a variety of surgical types and body parts, and it was necessary to construct a more versatile model. We achieved high accuracy by training the model with the addition of information about the surgical tools. We also showed that the understanding of the surgical scene, which has only been done for endoscopic surgery in existing studies, can be extended to other surgical procedures.
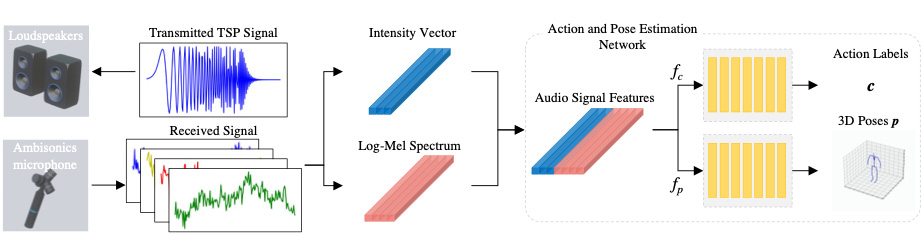
Human Pose Estimation based on acoustic signal
We proposed a novel framework for 3D pose estimation using acoustic signal.
The proposed method is mainly composed of 3 parts below.
(1) Sensing with TSP signals
(2) Creation of acoustic features (Log Mel Spectrum, Intensity Vector)
(3) Joint coordinate regression network using 1D CNN
By capturing changes in amplitude and direction of arrival when acoustic signals are reflected by the human body, it is now possible to obtain the 3D coordinates of joint points with high accuracy.
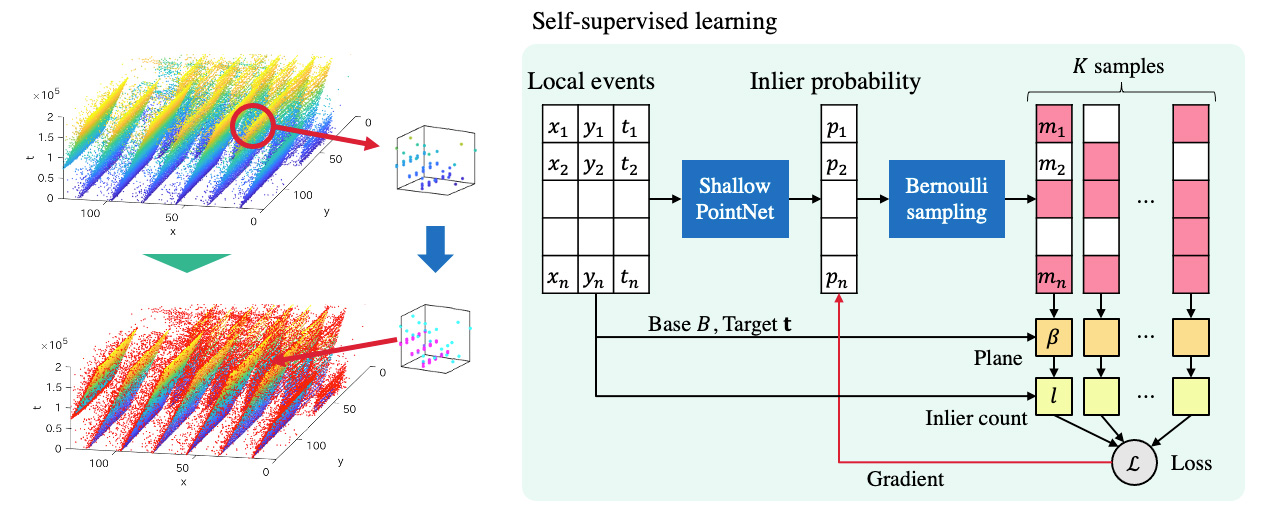
Self-Supervised Learning of Inlier Events for Event-based Optical Flow
Event cameras asynchronously report per-pixel intensity changes with high temporal resolution.
Their sparse and temporally precise nature is well suited for fast visual flow estimation.
The normal optical flow can be estimated by fitting a plane to spatio-temporal events.
However, least-squares plane fitting suffers from outliers due to the significant noise of events.
We propose a method of selecting the events supporting a plane before performing a fitting, using the inlier probability from a lightweight neural network that captures both global and local structures.
During inference, single-shot planar fitting is performed from only events with a higher inlier probability.
We model each event selection by a Bernoulli distribution with the inlier probability and train the network to maximize the inlier count while sampling in a self-supervised manner.
We verify that our event selection improves the accuracy of optical flow estimation compared to the existing rule-based method.
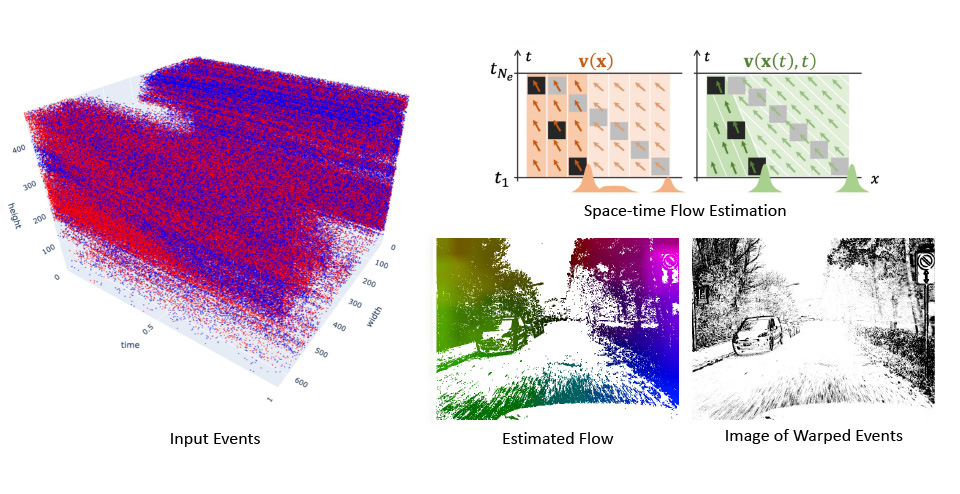
Optical Flow and Motion Estimation from Events
Diverse Plausible 360-Degree Image Outpainting for Efficient 3DCG Background Creation
In 3DCG creation, 360-degree images are used as background images representing the entire surroundings to create scenes efficiently. Our research addresses the problem of generating a 360-degree image by using a single normal-angle image as input and completing its surroundings. Our transformer-based method provides higher resolution and more natural-looking output images than prior methods’ results. Furthermore, the proposed method can output diverse result images for a single input, thus giving users many choices for their creation. In this way, this research aims to support users in efficient 3DCG creation with originality.

Document Shadow Removal with Foreground Detection Learning from Fully Synthetic Images
Shadow removal for document images is a major task for digitized document applications. Recent shadow removal models have been trained on pairs of shadow images and shadow-free images. However, obtaining a large-scale and diverse dataset is laborious and remains a great challenge. In this paper, we create a large-scale and diverse dataset with a graphic renderer. This process does not require capturing documents. The experiments showed that the networks (pre)trained on the proposed dataset provided better results than networks trained only on real datasets.
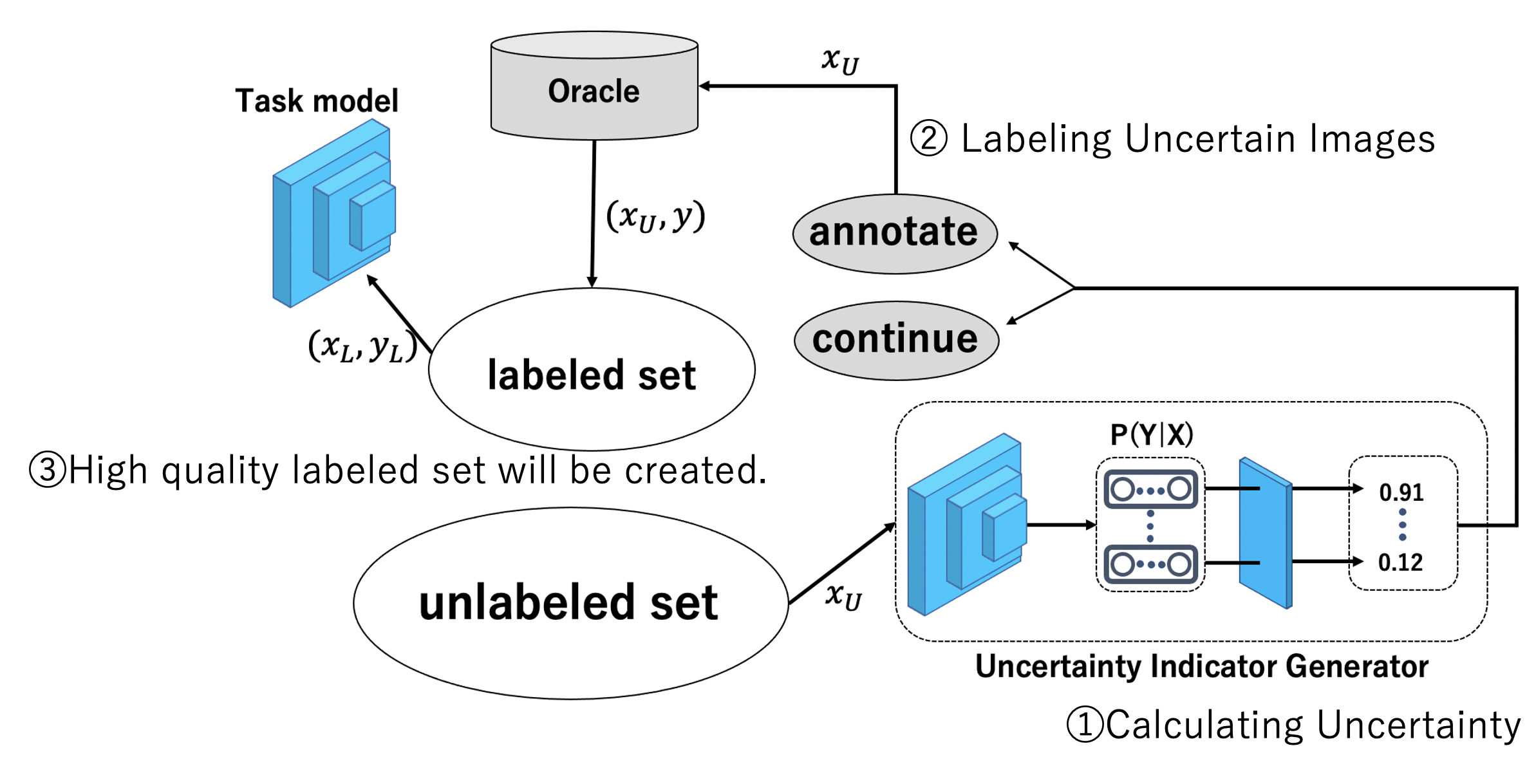
Non-Deep Active Learning for Deep Neural Networks
Active learning refers to label-efficient algorithms that use the most representative samples for labeling when creating training data. In this research, we propose a model that derives the most informative unlabeled samples from the output of a task model. The tasks are a classification problem, multi-label classification and a semantic segmentation problem. The model consists of an uncertainty indicator generator and a task model. After training the task model with labeled samples, the model predicts unlabeled samples, and based on the prediction results, the uncertainty indicator generator outputs an uncertainty indicator for each unlabeled sample. Samples with a higher uncertainty indicator are considered to be more informative and selected. As a result of experiments using multiple datasets, our model achieved better accuracy than conventional active learning methods and reduced execution time by a factor of 10.
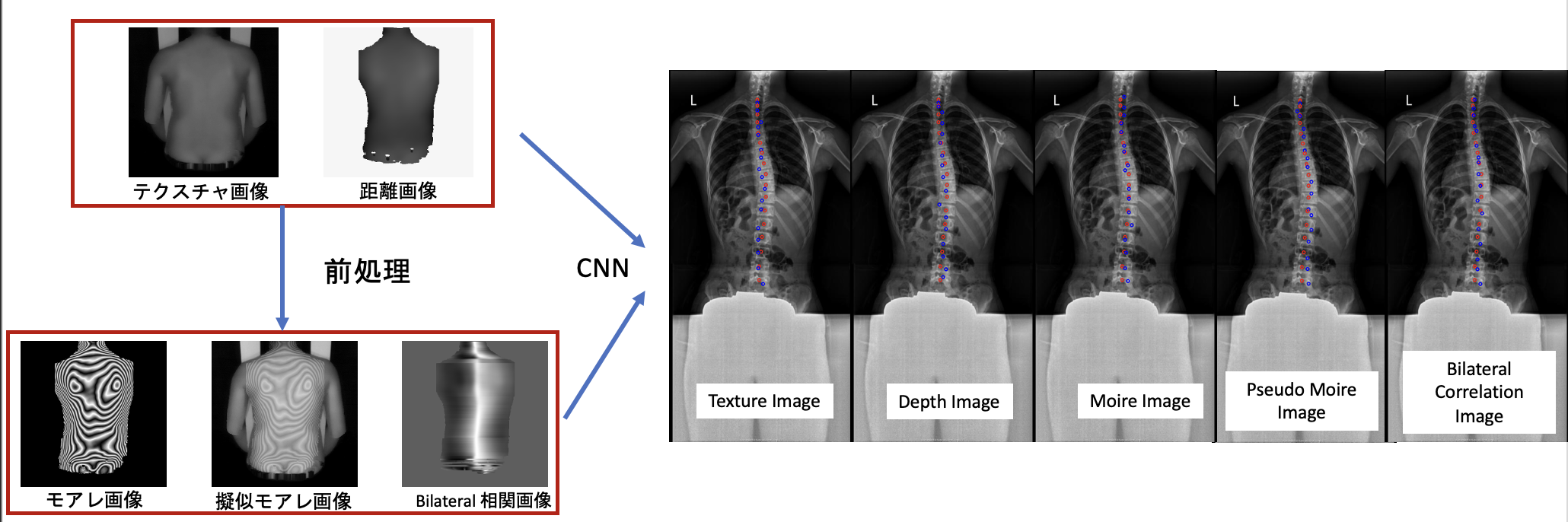
Detecting Spinal Alignment Through Depth Image
Recently, the production of Moire cameras, often used to detect scoliosis, have halted in recent years. This research proposes an alternative, non-invasive, and non-ionizing radioactive method to detect spinal alignment. Depth images are used to derive different types of images that are then trained using Convolutional Neural Networks (CNN) to predict the spinal alignment. Results indicate that Moire images reproduced from depth images produce the best spinal alignment.
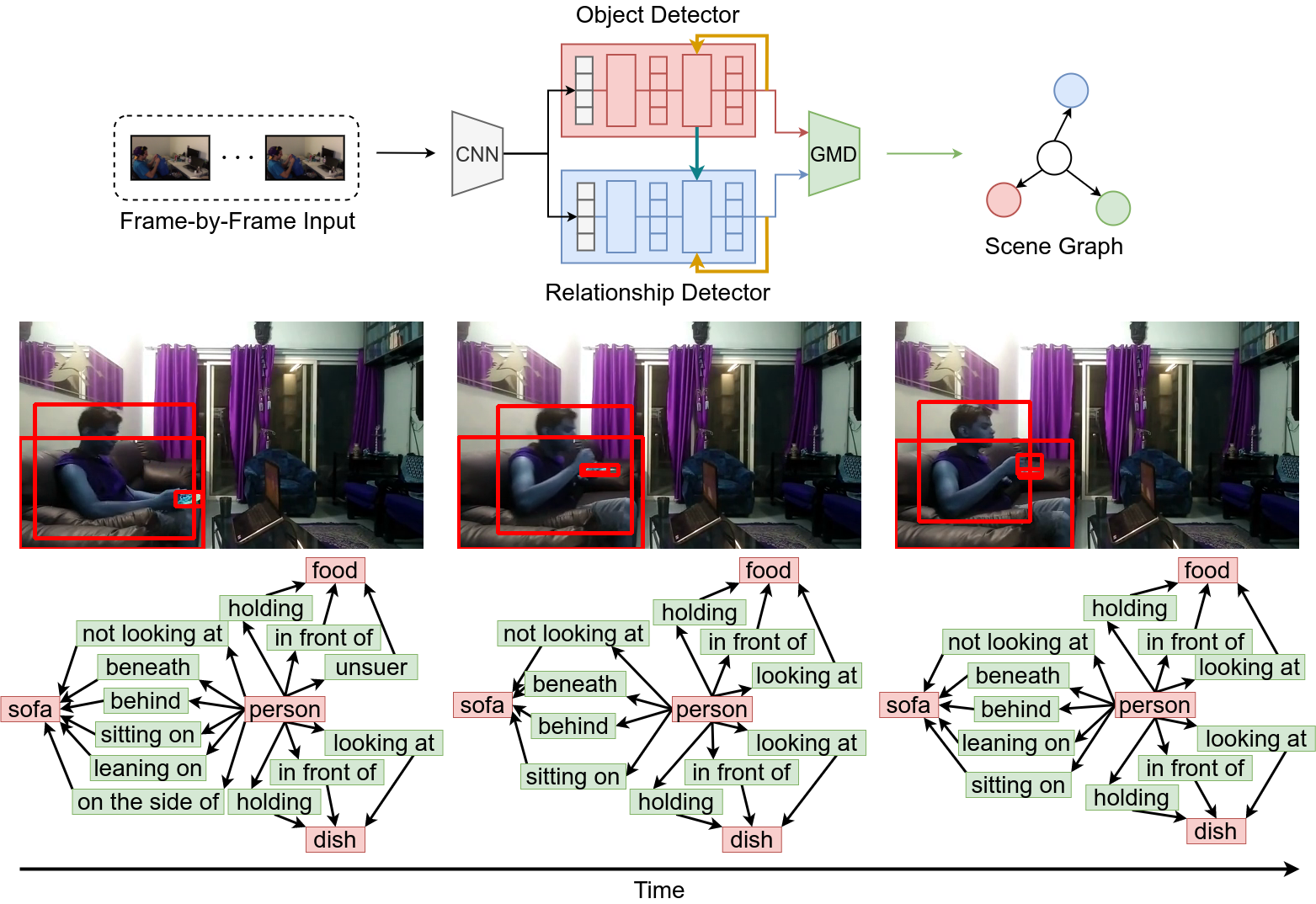
Joint Object and Relationship Detection on Dynamic Scene Graph Generation
Dynamic scene graphs, which represent detected objects and relationships as directed graphs, can clearly express the scene contexts in the video. Most previous studies adopt the two-stage method that detects relationships using detected objects. However, such methods cannot learn object and relationship detectors concurrently due to the one-way dependency from object detection to relationship prediction. Also, the inference time becomes slow because the two detectors are forwarded in series in two steps. To solve these issues, we propose a novel model that detects objects and relationships simultaneously in order to learn the detectors mutually and improve the inference performance.
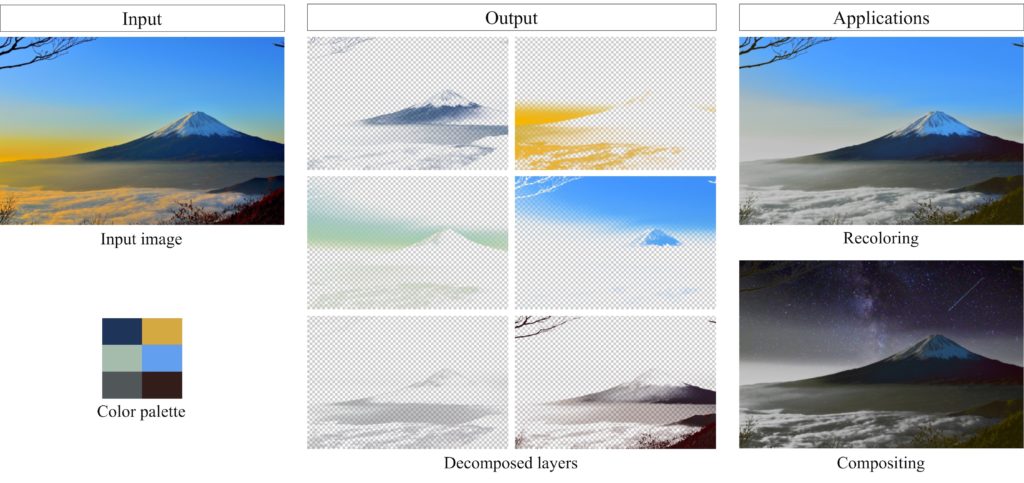
Fast Soft Color Segmentation
In this study, we deal with the problem of decomposing a single image into multiple RGBA layers containing only similar colors. Our proposed neural network-based method can be decomposed 300,000 times faster than conventional optimization-based methods. The advantage of its fast decomposition realizes novel applications, such as video recoloring and compositing.
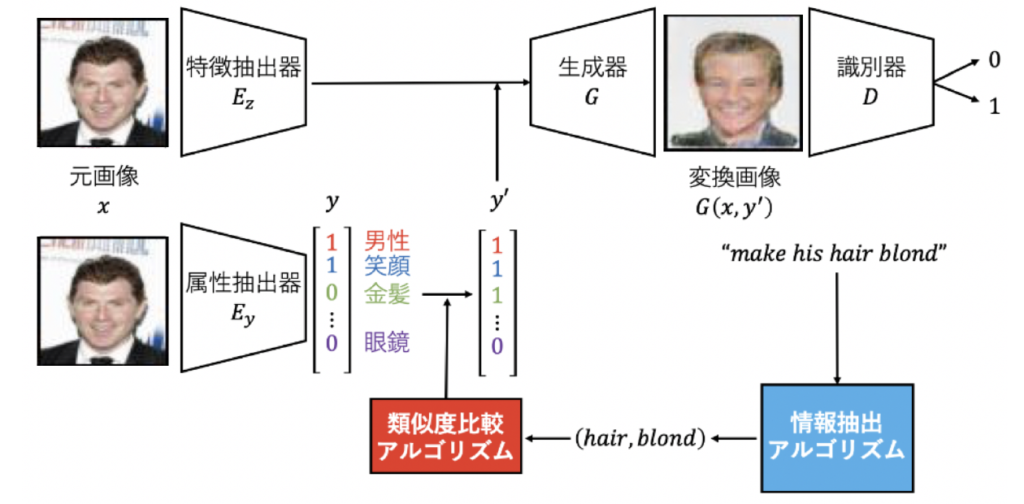
Visual Attribute Manipulation Using Natural Language Commands
In this paper, a novel setting is tackled in which a neural network generates object images with transferred attributes, by conditioning on natural language. Conventional methods for object image transformation have been known to bridge the gap between visual features by using an intermediate space of visual attributes. This paper builds on this approach and finds an algorithm to precisely extract information from natural language commands, completing this image translation model. The effectiveness of our information extraction model is experimented, with additional tests to see if the change in visual attributes is correctly seen in the image.
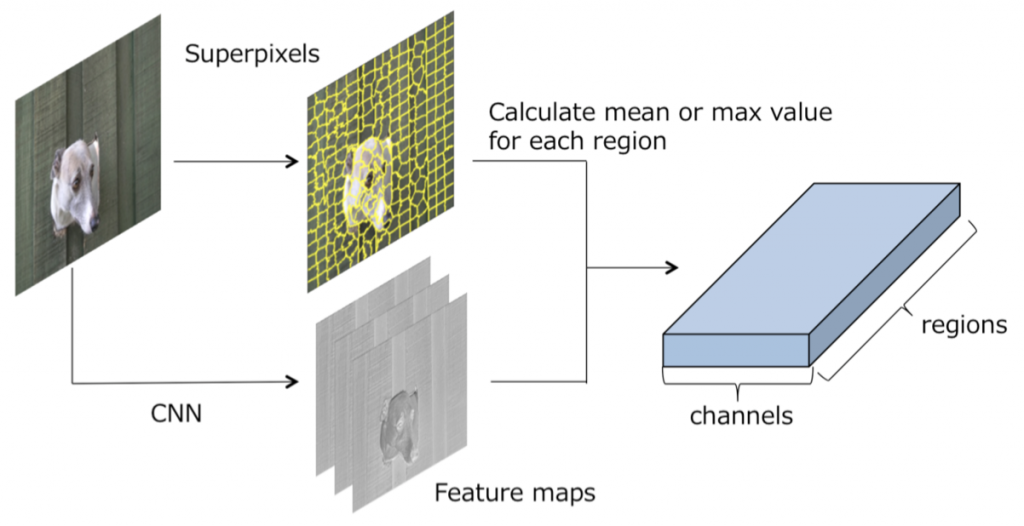
Graph Convolutional Neural Networks on superpixels for segmentation
A disadvantage of image domain segmentation using CNN is that spatial information is lost due to down-sampling by the pooling layer, and domain segmentation accuracy in the vicinity of object contours is reduced. Therefore, we proposed a graph convolution on superpixels as a different approach to prevent loss of information by pooling. In addition, we proposed a Dilated Graph Convolution, which extends the receptive field more effectively as an extension of the graph convolution. In a domain segmentation task using the HKU-IS data set, the proposed method outperformed a conventional CNN with the same configuration.
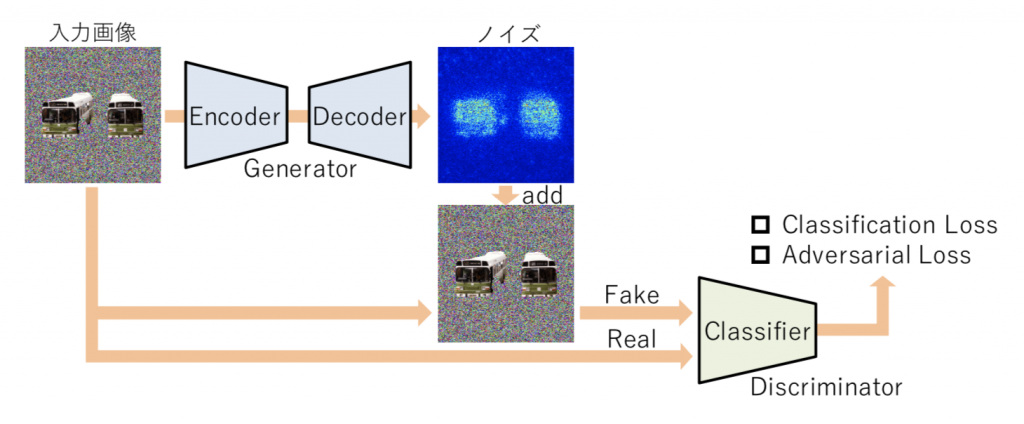
Saliency map generation in image discrimination using a CNN classifier
In general, when an image is input to a CNN and a specific output obtained, it is difficult to explain why such an output was obtained. In this study, we propose a saliency map generation method given by applying a Generative Adversarial Networks framework. In this system, learning takes place while two neural networks are made to compete. The first network learns to perform image identification. The second network learns to create an image that – if an image is input to the first network and can be successfully identified – is similar to this image but outputs an incorrect result when input into to the first network. For the second network to efficiently generate such an image, it suffices for the network to generate an image in which an image area important in the image identification of the first network is significantly changed. Such learning can be regarded as a saliency map, since it is possible to explicitly output an image area important in image identification.
Simultaneous execution of color adjustment and image completion by GAN
In this study, we propose a method of image completion while performing color adjustment in consideration of context in order to solve the problem of natural paste synthesis by color adjustment and image completion. In order to make the inserted object image explicitly appear in the completion area, we use CNN and Generic Adversarial Networks (GAN) for completion in consideration of context, and extract features related to the context from the entire background image. Furthermore, color adjustment taking context into consideration is carried out using the context features not only for image completion but also for color adjustment. In this way, a network is realized that simultaneously solves the problems of color adjustment and image completion.

Image Completion of 360-Degree Images by cGAN
This work proposes the novel problem setting that by using a known area from the 360-degree image as an input, the remainder of the image can be completed with the GANs. To do so, we propose the approach of two-stage generation using network architecture with series-parallel dilated convolution layers. Moreover, we present how to rearrange images for data augmentation, simplify the problem, and make inputs for training the 2nd stage generator. Our experiments show that these methods generate the distortion seen in 360-degree images in the outlines of buildings and roads, and their boundaries are clearer than those of baseline methods. Furthermore, we discuss and clarify the difficulty of our proposed problem. Our work is the first step towards GANs predicting an unseen area within a 360-degree space.

Image control after imaging by epsilon photography reconstruction using compression sensing
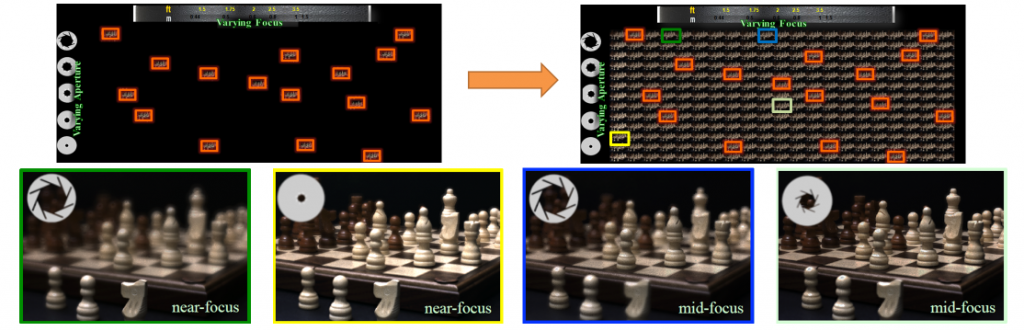
Conventionally, the photographer must select many parameters on the camera at the time of photographing. Light field imaging has enabled image control after shooting with respect to focus position and shooting viewpoint, but resolution is low, specialist hardware is required, and a completely flexible restoration of the focus position and aperture size is not possible. This study relates to technology to restore images taken with various parameters from ten images shot in succession using conventional cameras with parameters such as focus position, aperture size, exposure time and ISO changed. For example, we completely reconstruct the high dynamic range focus-aperture stack using consecutively shot images with pre-set parameters as the input.
Human movement analysis / behavior recognition technology
Our laboratory has acquired expressions for modeling human form and motion with high accuracy and efficiency, and advanced research on human recognition by machine learning. We are promoting research on robust human detection and tracking from images, posture estimation, motion analysis / prediction technology, and the eclectic application of these.
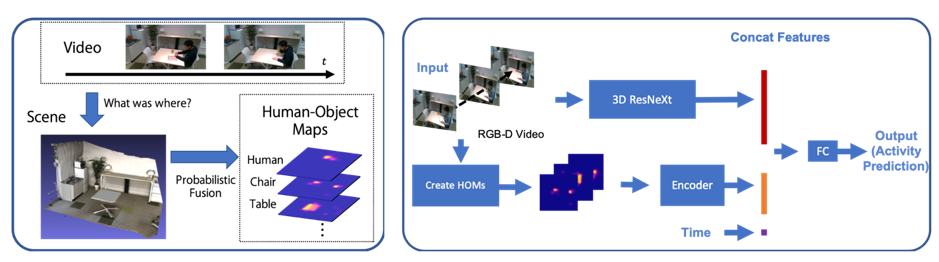
Daily activity recognition using human-object probability maps
Daily activities that occurs for several minutes to hours often includes several primitive actions which hinders action recognition from video inputs. In this research we observe “what”, “where”, “when”, and “how” humans performed daily activities and used these features to better recognize these daily activities. We introduced Human-Object Maps (HOMs) which represents probability maps of where humans and objects were and used these features for activity recognition. We evaluated the effectiveness of these maps using a dataset we have created which consists of several daily activities performed throughout the lab.
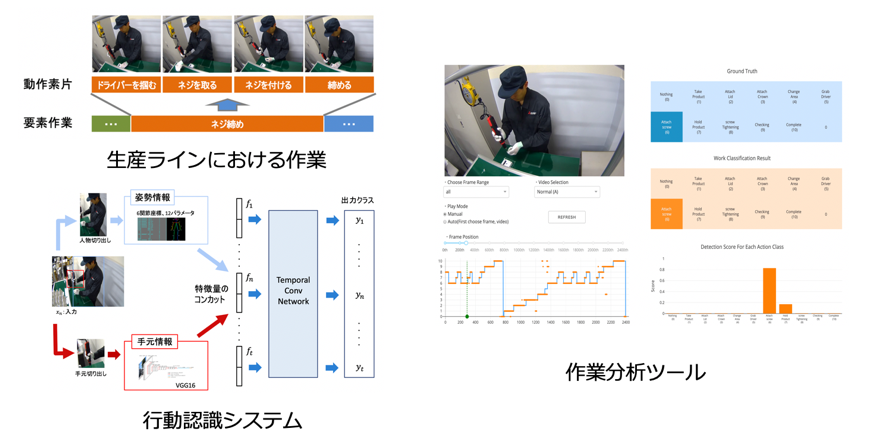
Fine-grained action segmentation for industrial production line
In this research, we aim to tackle the fine-grained action recognition task using working videos taken in product line scenes. Unlike general datasets for action recognition, our working dataset consists of fine-grained actions, which worker only uses hands and arms. This causes the difficulty to detect frame wise action using RGB image as the input for each frame. To tackle this problem, we focused on combining pose features and hand features. Pose features are for capturing the movements of arms, and hand features are for capturing the movements of hands and also gaining the information of which tool the worker is using. By using our original dataset, we showed that are model are able to secure high recognition rate, and also robust to the variety of environments and workers.
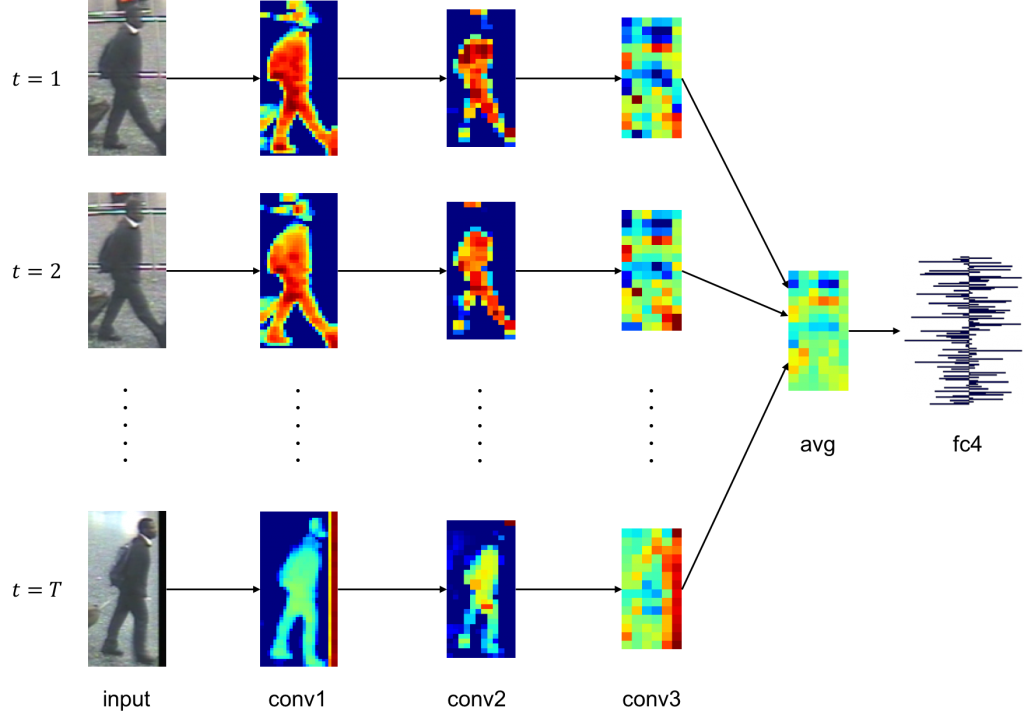
Human re-identification by distance learning using CNN
We proposed a new method to re-identify people by learning the similarity of people in moving images by a convolution neural network. Feature-extraction is carried out on each moving human image by a convolution neural network, and the distance between embedding vectors is mapped to Euclidean space so as to directly correspond to the distance indicator between people. Update of parameters is carried out once having taken into account all triplet groups that can be taken within the mini-batch by an improved parameter learning method called Entire Triplet Loss . The generalization performance of the network was greatly improved by such a simple change of the parameter updating method, and the embedding vector was more easily separated for each person. In evaluation experiments, the method achieved the most advanced re-identification rate for an international data set.
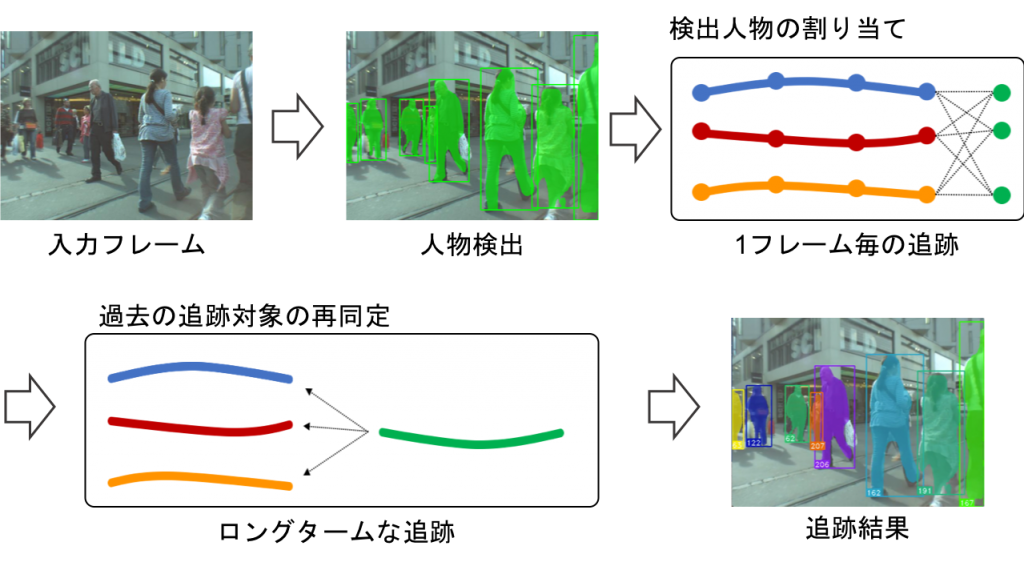
On-line multiple object tracking using re-identification of tracking trajectory
Many existing methods of tracking multiple objects by on-line processing adopt a tracking-by-detection approach that chronologically assigns object rectangles obtained by performing object detection in every frame of a moving image. However, existing methods could not track objects that were not detected by the object detector due to masking or the like. Therefore, we propose a method to transfer a lost object to a tracking state once again by re-identification of the tracking trajectory. Embedding vectors expressing the high dimensional appearance features of the object are acquired using a convolution neural network and re-identification of the tracking trajectory is carried out according to the distance of the embedding vector between tracking trajectories. At this time, using the mask image of the object obtained by area division as the input of the network enables robust re-identification determination with respect to change in background. Furthermore, since the determination of the re-identification of the tracking trajectory pair is performed based on the distance between low-dimensional vectors, the increase in calculation cost due to the determination is small.
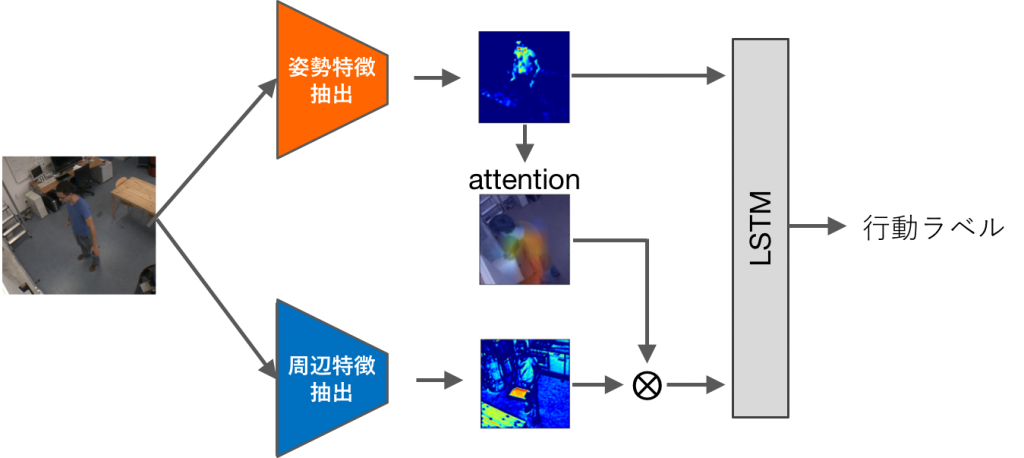
Time sequence behavior recognition in a behavior transition video
In this study, we considered the issue behavior recognition conducted on moving images in which multiple actions are continuously transitioning, and proposed various time series analyses using hierarchical LSTM. In addition, we proposed the effective use of peripheral features by incremental learning of peripheral information and filtering of peripheral features by posture characteristics centered on posture information robust to environmental change. We obtained an improvement over the conventional method for behavior recognition tasks conduced on behavior transition video using a data set.
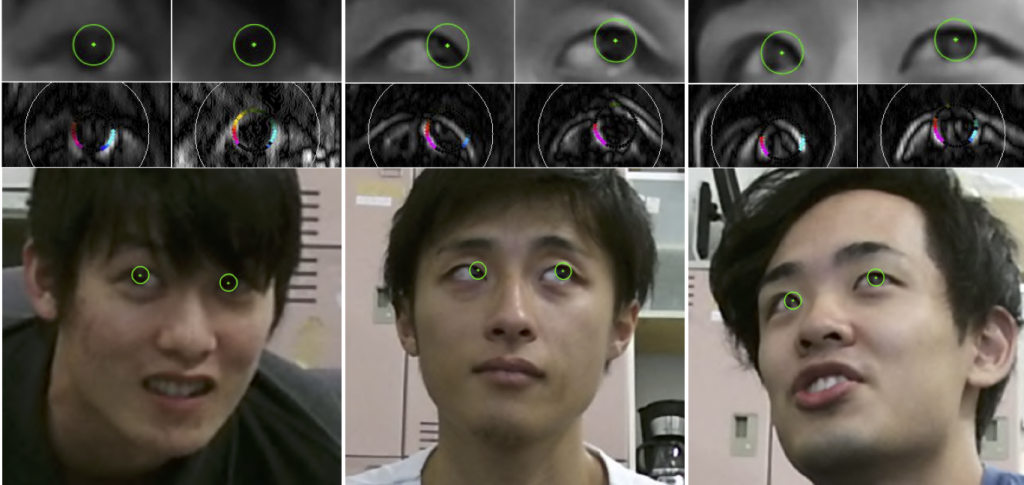
Calibration free gaze estimation
Many existing gaze estimation methods use special equipment such as infrared LEDs and distance sensors, or require prior calibration work. In this study, we propose a calibration-free gaze point estimation method for cameras that can be used with a wide range of head positions, in order to realize a gaze estimation method suitable for practical use in society. Based on a robust iris tracking method independent of resolution, we demonstrate the possibility of realizing calibration-free gaze estimation in an extensive space using a gaze estimation method consisting of facial feature point detection, iris tracking, and gazing point estimation. We aim to apply this to various fields.
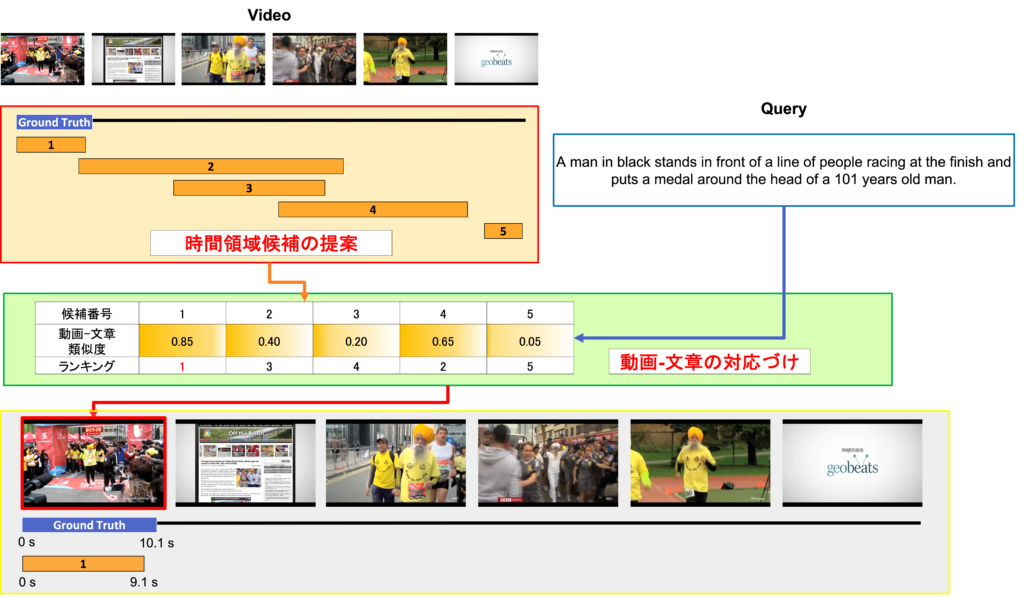
Video-Text Retrieval for understanding more complex activities in videos
We aim to develop a more advanced ‘video-text retrieval/detection’ system that learns matching and alignment between videos/moments and its textual descriptions.
Our research goals are mainly twofold:
- Video Moment Retrieval (Natural Language Moment Localization): Given a textual query, we search a corresponding temporal moment within a video.
- Video-text retrieval with a self-supervised word-like 3D unit discovery in a video.
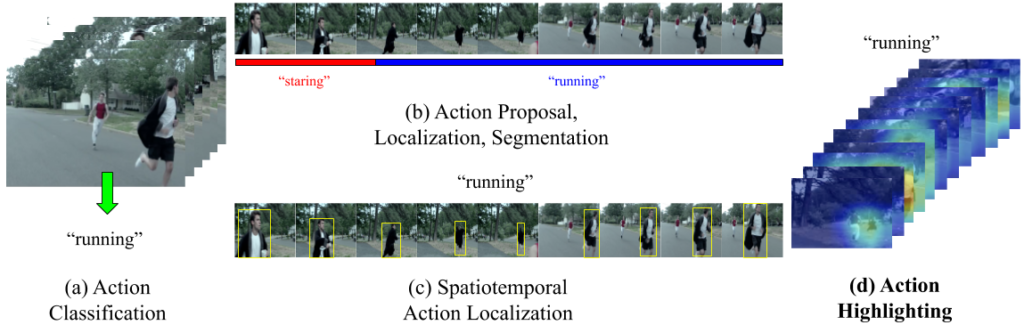
Retrieving and Highlighting Action with Spatiotemporal Reference
In this paper, we present a framework that jointly retrieves and spatiotemporally highlights actions in videos by enhancing current deep cross-modal retrieval methods. Our work takes on the novel task of action highlighting, which visualizes where and when actions occur in an untrimmed video setting. Leveraging weak supervision from annotated captions, our framework acquires spatiotemporal relevance maps and generates local embeddings which relate to the nouns and verbs in captions.
[/su_animate]
Moment-Sentence Grounding from Temporal Action Proposal
Deep learning in Vision and Language, which is one of a challenging task in multi-modal learning, is gaining more attention these days.
In this paper, we tackle with temporal moment retrieval. Given an untrimmed video and a description query, temporal moment retrieval aims to localize the temporal segment within the video that best describes the textual query. Our approach is based on mainly two stage models. First, temporal proposals are obtained by using the existing temporal action proposal method. Second, the best proposal is predicted by the similarity score between visual features and linguistic features.
Sports video analysis
In sports, quantitative play analysis from images is important in improving the level of competition and motivation of athletes, supporting coaching, and providing new broadcast video content. Our laboratory is conducting research on methods and systems for sport image analysis which can be practically utilized in the field of various sports.
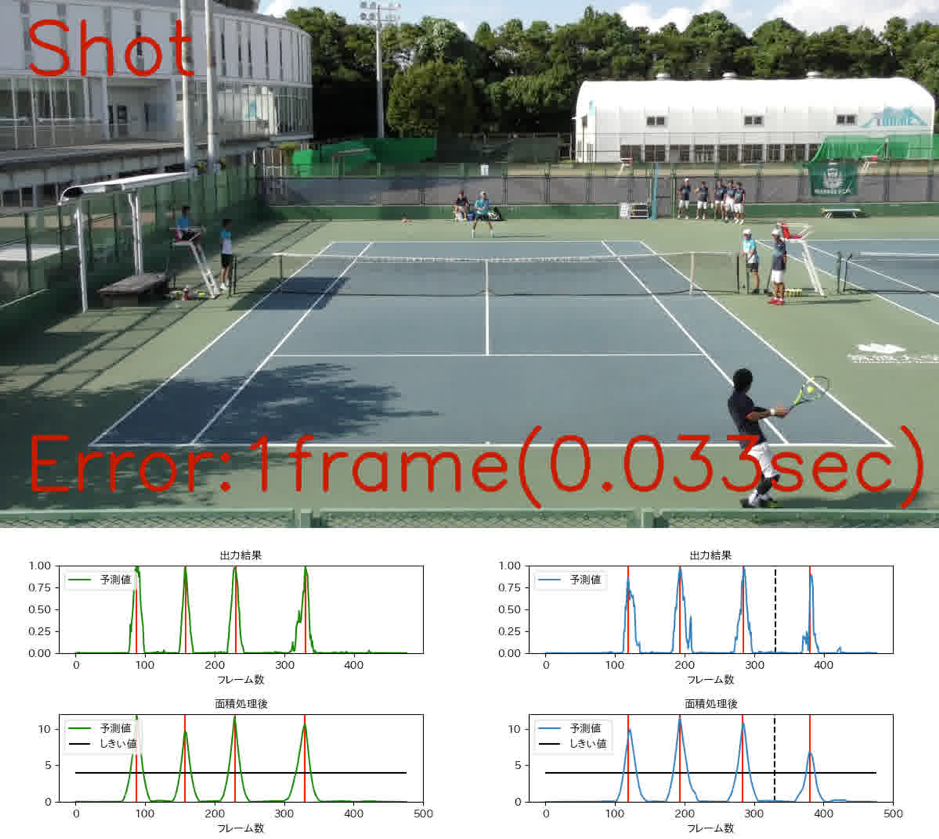
Shot Detection in Tennis Games
In this study, we propose a shot detection method in tennis games, based on a movie. Conventional method depends on detecting the ball, but our proposed method can recognize the ball, rackets and players, achieving a higher precision. Shot detectors for other racquet sports as well as further analytics to provide features like shot classification, rally analysis and recommendations, can easily be built with our proposed solution. Moreover, by adapting to interaction between humans and objects, such as touching and tapping, our method can also be applied to a user interface device.
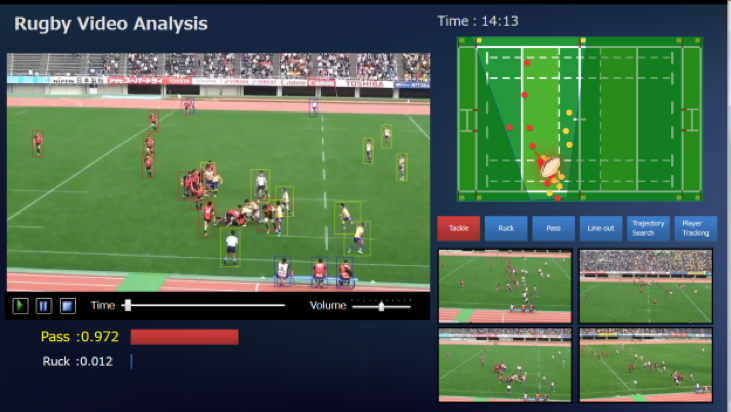
Rugby video analysis system
In this study, we developed technology to accurately map the trajectory of movement of the ball/players from a single camera image on a 2D field using hybrid image analysis that carries out ball detection/tracking by feature quantity design method and selection detection/tracking by deep learning method. In addition, automatic play was classified by deep learning, and the automation of the tagging work of the main players, which was conventionally done manually, was studied. This technology is applicable not only to rugby but also to various other sports, and it is expected to be adopted in applications other than sports, such as industrial fields.
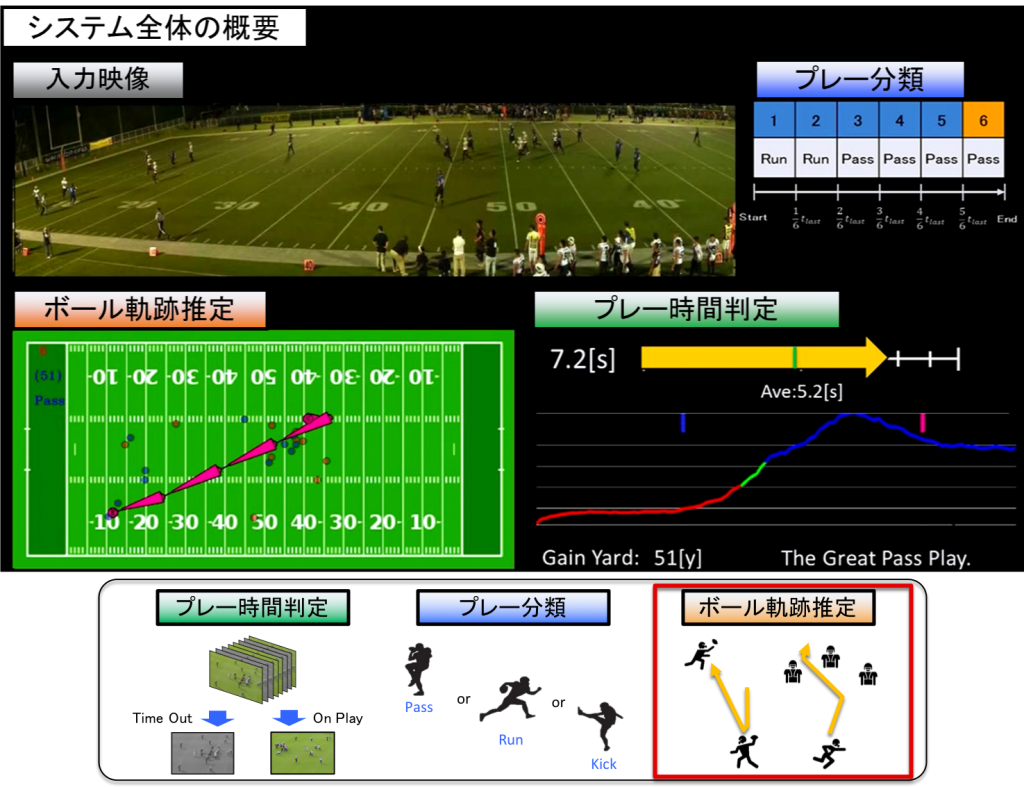
American football video analysis system
Shielding of players by other players is particularly common and there are many patterns of player motion during American football and other team sports. Play time is judged using a Global Motion Feature, such as player position and motion information for the entire field from videos of American football. Furthermore, after calculating the positions of two distinctive features i.e. the play start and end position, and carrying out the classifications of pass, run, and kick, which are American football play patterns, we realize a method of estimating the ball trajectory, which has important information for game analysis without detecting the ball itself. This enables the acquisition of play time / play classification / ball trajectory information, and the automatic creation of a game analysis database.
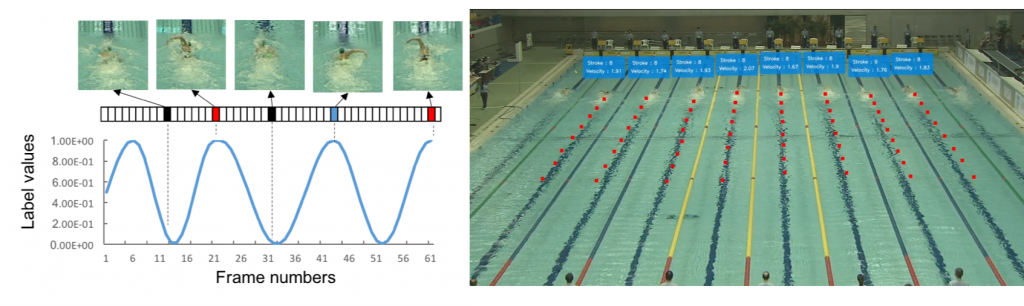
Swimmer tracking system
We propose an athlete tracking and stroke estimation method for videos of swimming events, which is robust to splashing and other noise and does not depend on the shooting environment. Athletes are detected from the video and tracked. The feature value of the athlete image is acquired by inputting the detected athlete images into a CNN. Furthermore, the stroke is estimated by creating a temporal sequence from the obtained feature value and inputting it into MultiLSTM. Based on the finally obtained athlete position and stroke information, we visualize the speed and stroke of the athlete, and aim to amplify the sense of live broadcast by superimposing it on the video.
Intelligent robotics
To date, robots have performed various services based on careful instructions. In our laboratory, we are conducting R&D on an intelligent robot that behaves appropriately by observing the situation and people, using real-time human behavior recognition, object/environment recognition technology and past action logs to obtain various forms of “awareness”.
Object Manipulation Task Generation by Self-supervised Learning of Stationary Layouts
We propose a method for generating the operations to reconstruct a stationary object’s layout from an input image that has a non-stationary layout. The proposed method is an encoder-decoder–type network with special layers for estimating a list of operations which includes the operation type, object class, and position. The network can trained by a self-supervised manner. From an experiment of the operation generation using real images, it is confirmed that the our method have enabled generating the operations that change the object’s layout in an input scene to a stationary layout in real time.

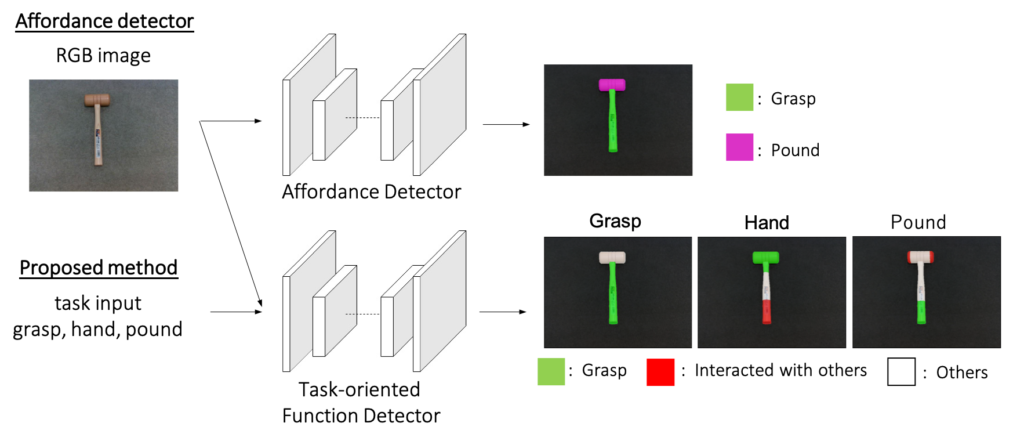
Task-oriented Function Detection based on an operational task
We propose a novel representation to describe functions of an object, Task-oriented Function, which takes the place of Affordance in the field of Robotics Vision. We also propose a CNN-based network to detect Task-oriented Function. This network takes as input an operational task as well as a RGB image and assign each pixel to an appropriate label to every task. Because the outputs from the network differ depending on tasks, Task-oriented Function makes it possible to describe a variety of ways to use an object. We introduce a new dataset for Task-oriented Function, which contains about 1200 RGB images and 6000 annotations assuming five tasks. Our proposed method reached 0.80 mean IOU in our dataset.
Tactile Logging: A method of describing the operation history on an object surface based on human motion analysis
We propose a method to analyze a demonstration of a tool operated by a human and shot as an RGB-D movie. The proposed method estimates the interaction that occurs with the object while tracking the human pose and the three-dimensional position and attitude of the object subject to operation. This result is recorded as a time-series usage history (tactile log) onthe surface of the 3D model of the object. The tactile log is a new data expression for manifesting the ideal method of using the object, and it can be used for generating operations of gripping and handling “natural” tools by robot arms.

6-degree-of-freedom attitude estimation of similar-shaped objects focusing on the spatial arrangement of functional attributes
We propose a 6-degree-of-freedom attitude estimation method that can be operated even if the same 3D model as the object does not exist. Even if the design of tools in the same category is different, the arrangement of the roles (function attributes) of each part is considered to be common. In the proposed method, this is used as a means for attitude estimation. We confirmed that the reliability of attitude estimation improves by simultaneously optimizing consistency between arrangements of functional attributes and consistency between shapes. In actual use, this has the advantage that if just one 3D model of an object of a target category is associated with a function attribute or a grasping method, it is possible to handle an actual object just as it is, eliminating the necessity to prepare model data for each object.

[/su_animate]
Real world sensing
Image sensing technology is expected to be utilized in various situations in the real world. Our laboratory aims to utilize new image sensing technology in various fields such as automobiles and medical care.
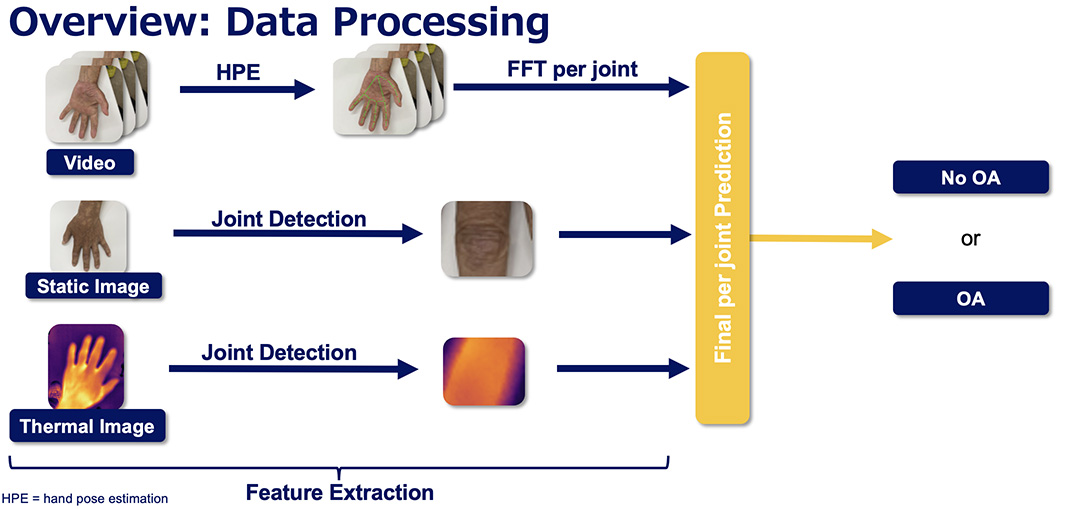
Detection of Osteoarthritis from Multimodal Hand Data
Recently, as the population around the world keeps aging, the number of people affected by osteoarthritis (OA) of the hand, a joint disease associated with high age, has been steadily increasing. Currently, OA is detected by well-experienced doctors using radiographic analysis or ultrasonography so technology is needed that can reduce the damage to patients and improve diagnostic efficiency. In this research, we propose a pipeline that is based on video, image and thermal data to detect OA automatically. Training and testing are performed on our own over 200 patients data that we newly collected in Keio University Hospital. This is the first to predict OA for each hand joint.
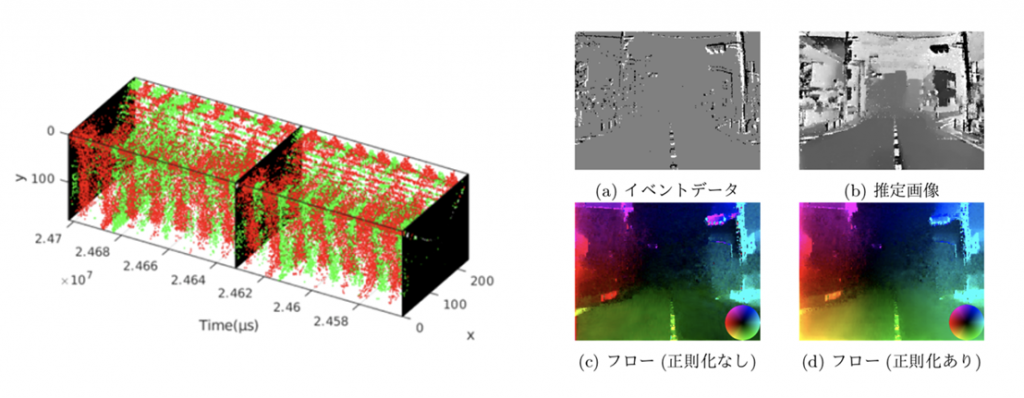
Optical flow estimation by in-vehicle event camera
We propose regularization specialized to in-vehicle camera scenes, which utilize characteristics relating to vehicle motion characteristics and focus of expansion (FOE) for optical flow estimation using event cameras. FOE is defined as the intersection of the translation axis of the camera and the image plane. The optical flow has the feature of becoming radial from the FOE when the component due to rotation is excluded from the optical flow of the surrounding environmental due to the motion of the vehicle itself. The proposed regularization restricts the direction of the optical flow using this feature. The usefulness of this regularization was demonstrated by evaluating the rotation parameters estimated during the method.
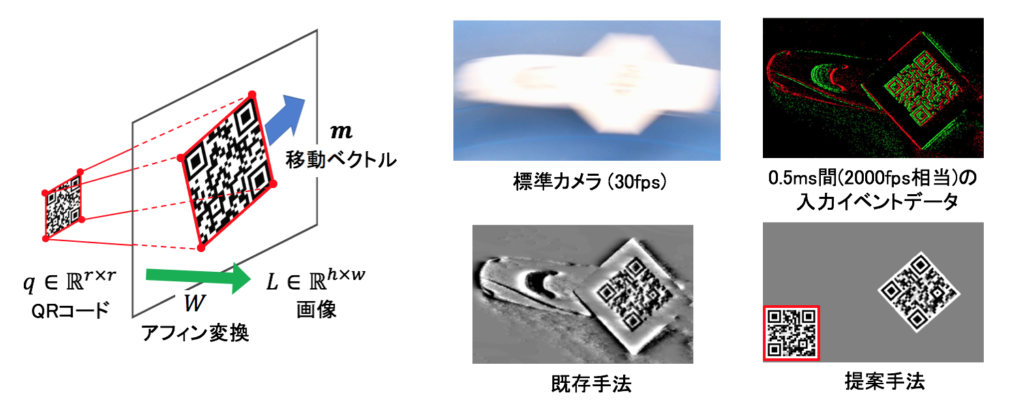
Robust QR-code recognition by using event camera
QR codes are widely used on production lines in factory automation. However, there is a problem that blurring occurs due to lighting conditions and the speed of the belt conveyor. Against this problem, event cameras asynchronously capture changes in luminance for each pixel and have excellent advantages such as high temporal resolution and high dynamic range. In this research, we proposed a method of estimating QR code robustly from event data by optimizing in QR code space which is more restricted than image space.
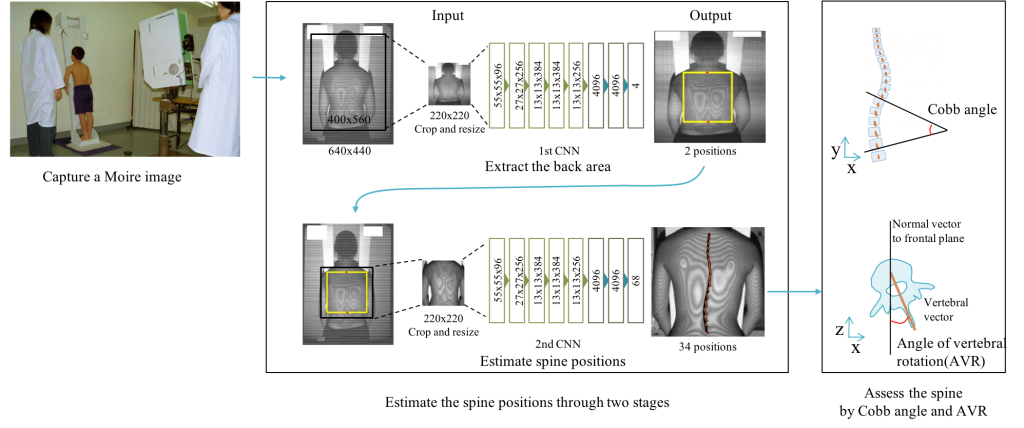
Scoliosis screening by estimation of spinal column alignment from moire topographic images of the back
In this study, we propose a method to calculate the Cobb angle and VR angle necessary for fully automatic scoliosis screening, using input of moire topographic images of the back of subjects without X-ray exposure. Using a moire images and X-ray images, we propose a method of estimating spinal column alignment coordinates with high precision and a method to automatically calculate Cobb angle and VR angle from spinal column alignment information from just a moire image by CNN learning with feature point coordinates of a spinal column extracted from an X-ray image by a physician as teacher data. We demonstrated the effectiveness of the proposed method on an independently constructed dataset. Currently, we are investigating a method to estimate 3D spinal column alignment from 3D scan data of the back.
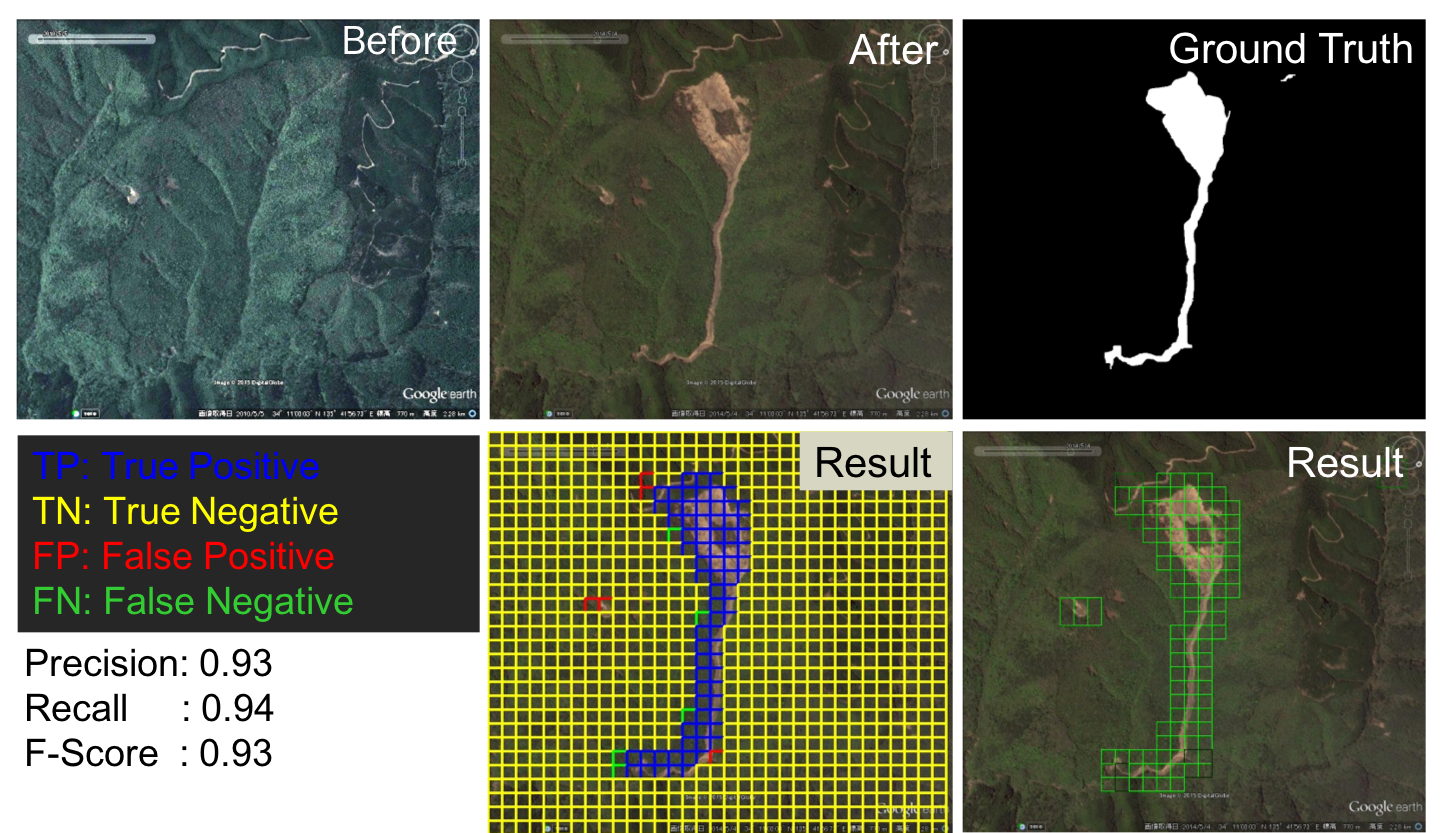
Application of Change Detection via Convolutional Neural Networks in Remote Sensing
Analysis of remote sensing imagery plays an increasingly vital role in the environment and climate monitoring, especially in detecting and managing changes in the environment. Since obtaining satellite imagery or aerial imagery are getting more comfortable in recent years, changes in landscape due to disaster are highly in demand. In this paper, we propose automatic landscape change detection especially landslide and flood detection by implementing convolutional neural network (CNN) in extracting the feature more effectively. CNN is robust to shadow, able to obtain the characteristic of disaster adequately and most importantly able to overcome misdetection or misjudgment by operators, which will affect the effectiveness of disaster relief. The neural network consists of 2 phases: training phase and testing phase. We created our own training data patches of pre-disaster and post-disaster from Google Earth Aerial Imagery, which we are currently focusing on two countries: Japan and Thailand. Each disaster’s training data set consists of 50000 patches, and all patches are trained in CNN to extract region where the disaster occurred without delay. The results show the accuracy of our system in around 80%-90% of both disaster detections. Based on the promising results, the proposed method may assist in our understanding of the role of deep learning in disaster detection.